\"\n",
+ " }},\n",
+ " ...\n",
+ "]\n",
+ "```\n",
+ "\"\"\"\n",
+ "\n",
+ "full_response = \"\"\n",
+ "\n",
+ "for chunk in pi_client.chat_completions(\n",
+ " messages=[{\"role\": \"user\", \"content\": retrieval_prompt}],\n",
+ " doc_id=doc_id,\n",
+ " stream=True\n",
+ "):\n",
+ " print(chunk, end='', flush=True)\n",
+ " full_response += chunk"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "d-Y9towQ_CiF"
+ },
+ "source": [
+ "### Извлечь JSON с результатами извлечения\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 59,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "rwjC65oB05Tt",
+ "outputId": "64504ad5-1778-463f-989b-46e18aba2ea6"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Note: you may need to restart the kernel to use updated packages.\n",
+ "[{'content': '## 6. Evaluation\\n'\n",
+ " '\\n'\n",
+ " 'The evaluation of context-engineered systems presents '\n",
+ " 'unprecedented challenges that transcend traditional language '\n",
+ " 'model assessment paradigms. These systems exhibit complex, '\n",
+ " 'multi-component architectures with dynamic, context-dependent '\n",
+ " 'behaviors requiring comprehensive evaluation frameworks that '\n",
+ " 'assess component-level diagnostics, task-based performance, and '\n",
+ " 'overall system robustness [841, 1141].\\n'\n",
+ " '\\n'\n",
+ " 'The heterogeneous nature of context engineering '\n",
+ " 'components-spanning retrieval mechanisms, memory systems, '\n",
+ " 'reasoning chains, and multi-agent coordination-demands '\n",
+ " 'evaluation methodologies that can capture both individual '\n",
+ " 'component effectiveness and emergent system-level behaviors '\n",
+ " '[314, 939].\\n'\n",
+ " '\\n'\n",
+ " '### 6.1. Evaluation Frameworks and Methodologies\\n'\n",
+ " '\\n'\n",
+ " 'This subsection presents comprehensive approaches for evaluating '\n",
+ " 'both individual components and integrated systems in context '\n",
+ " 'engineering.\\n'\n",
+ " '\\n'\n",
+ " '#### 6.1.1. Component-Level Assessment\\n'\n",
+ " '\\n'\n",
+ " 'Intrinsic evaluation focuses on the performance of individual '\n",
+ " 'components in isolation, providing foundational insights into '\n",
+ " 'system capabilities and failure modes.\\n'\n",
+ " '\\n'\n",
+ " 'For prompt engineering components, evaluation encompasses prompt '\n",
+ " 'effectiveness measurement through semantic similarity metrics, '\n",
+ " 'response quality assessment, and robustness testing across '\n",
+ " 'diverse input variations. Current approaches reveal brittleness '\n",
+ " 'and robustness challenges in prompt design, necessitating more '\n",
+ " 'sophisticated evaluation frameworks that can assess contextual '\n",
+ " 'calibration and adaptive prompt optimization $[1141,669]$.',\n",
+ " 'page': 45},\n",
+ " {'content': 'Long context processing evaluation requires specialized metrics '\n",
+ " 'addressing information retention, positional bias, and reasoning '\n",
+ " 'coherence across extended sequences. The \"needle in a haystack\" '\n",
+ " \"evaluation paradigm tests models' ability to retrieve specific \"\n",
+ " 'information embedded within long contexts, while multi-document '\n",
+ " 'reasoning tasks assess synthesis capabilities across multiple '\n",
+ " 'information sources. Position interpolation techniques and '\n",
+ " 'ultra-long sequence processing methods face significant '\n",
+ " 'computational challenges that limit practical evaluation '\n",
+ " 'scenarios [737, 299].\\n'\n",
+ " '\\n'\n",
+ " 'Self-contextualization mechanisms undergo evaluation through '\n",
+ " 'meta-learning assessments, adaptation speed measurements, and '\n",
+ " 'consistency analysis across multiple iterations. Self-refinement '\n",
+ " 'frameworks including Self-Refine, Reflexion, and N-CRITICS '\n",
+ " 'demonstrate substantial performance improvements, with GPT-4 '\n",
+ " 'achieving approximately 20\\\\% improvement through iterative '\n",
+ " 'self-refinement processes [741, 964, 795]. Multi-dimensional '\n",
+ " 'feedback mechanisms and ensemble-based evaluation approaches '\n",
+ " 'provide comprehensive assessment of autonomous evolution '\n",
+ " 'capabilities [583, 710].\\n'\n",
+ " '\\n'\n",
+ " 'Structured and relational data integration evaluation examines '\n",
+ " 'accuracy in knowledge graph traversal, table comprehension, and '\n",
+ " 'database query generation. However, current evaluation '\n",
+ " 'frameworks face significant limitations in assessing structural '\n",
+ " 'reasoning capabilities, with high-quality structured training '\n",
+ " 'data development presenting ongoing challenges. LSTM-based '\n",
+ " 'models demonstrate increased errors when sequential and '\n",
+ " 'structural information conflict, highlighting the need for more '\n",
+ " 'sophisticated benchmarks testing structural understanding '\n",
+ " '$[769,674,167]$.\\n'\n",
+ " '\\n'\n",
+ " '#### 6.1.2. System-Level Integration Assessment\\n'\n",
+ " '\\n'\n",
+ " 'Extrinsic evaluation measures end-to-end performance on '\n",
+ " 'downstream tasks, providing holistic assessments of system '\n",
+ " 'utility through comprehensive benchmarks spanning question '\n",
+ " 'answering, reasoning, and real-world applications.\\n'\n",
+ " '\\n'\n",
+ " 'System-level evaluation must capture emergent behaviors arising '\n",
+ " 'from component interactions, including synergistic effects where '\n",
+ " 'combined components exceed individual performance and potential '\n",
+ " 'interference patterns where component integration degrades '\n",
+ " 'overall effectiveness [841, 1141].\\n'\n",
+ " '\\n'\n",
+ " 'Retrieval-Augmented Generation evaluation encompasses both '\n",
+ " 'retrieval quality and generation effectiveness through '\n",
+ " 'comprehensive metrics addressing precision, recall, relevance, '\n",
+ " 'and factual accuracy. Agentic RAG systems introduce additional '\n",
+ " 'complexity requiring evaluation of task decomposition accuracy, '\n",
+ " 'multi-plan selection effectiveness, and memory-augmented '\n",
+ " 'planning capabilities. Self-reflection mechanisms demonstrate '\n",
+ " 'iterative improvement through feedback loops, with MemoryBank '\n",
+ " 'implementations incorporating Ebbinghaus Forgetting Curve '\n",
+ " 'principles for enhanced memory evaluation [444, 166, 1372, 1192, '\n",
+ " '41].\\n'\n",
+ " '\\n'\n",
+ " 'Memory systems evaluation encounters substantial difficulties '\n",
+ " 'stemming from the absence of standardized assessment frameworks '\n",
+ " 'and the inherently stateless characteristics of contemporary '\n",
+ " 'LLMs. LongMemEval offers 500 carefully curated questions that '\n",
+ " 'evaluate fundamental capabilities encompassing information '\n",
+ " 'extraction, temporal reasoning, multi-session reasoning, and '\n",
+ " 'knowledge updates. Commercial AI assistants exhibit $30 \\\\%$ '\n",
+ " 'accuracy degradation throughout extended interactions, '\n",
+ " 'underscoring significant deficiencies in memory persistence and '\n",
+ " 'retrieval effectiveness [1340, 1180, 463, 847, 390]. Dedicated '\n",
+ " 'benchmarks such as NarrativeQA, QMSum, QuALITY, and MEMENTO '\n",
+ " 'tackle episodic memory evaluation challenges [556, 572].\\n'\n",
+ " '\\n'\n",
+ " 'Tool-integrated reasoning systems require comprehensive '\n",
+ " 'evaluation covering the entire interaction trajectory, including '\n",
+ " 'tool selection accuracy, parameter extraction precision, '\n",
+ " 'execution success rates, and error recovery capabilities. The '\n",
+ " 'MCP-RADAR framework provides standardized evaluation employing '\n",
+ " 'objective metrics for software engineering and mathematical '\n",
+ " 'reasoning domains. Real-world evaluation reveals',\n",
+ " 'page': 46},\n",
+ " {'content': 'significant performance gaps, with GPT-4 completing less than '\n",
+ " '50\\\\% of tasks in the GTA benchmark, compared to human '\n",
+ " 'performance of $92 \\\\%$ [314, 1098, 126, 939]. Advanced '\n",
+ " 'benchmarks including BFCL (2,000 testing cases), T-Eval (553 '\n",
+ " 'tool-use cases), API-Bank (73 APIs, 314 dialogues), and ToolHop '\n",
+ " '( 995 queries, 3,912 tools) address multi-turn interactions and '\n",
+ " 'nested tool calling scenarios [263, 363, 377, 1264, 160, 835].\\n'\n",
+ " '\\n'\n",
+ " 'Multi-agent systems evaluation captures communication '\n",
+ " 'effectiveness, coordination efficiency, and collective outcome '\n",
+ " 'quality through specialized metrics addressing protocol '\n",
+ " 'adherence, task decomposition accuracy, and emergent '\n",
+ " 'collaborative behaviors. Contemporary orchestration frameworks '\n",
+ " 'including LangGraph, AutoGen, and CAMEL demonstrate insufficient '\n",
+ " 'transaction support, with validation limitations emerging as '\n",
+ " 'systems rely exclusively on LLM self-validation capabilities '\n",
+ " 'without independent validation procedures. Context handling '\n",
+ " 'failures compound challenges as agents struggle with long-term '\n",
+ " 'context maintenance encompassing both episodic and semantic '\n",
+ " 'information [128, 394, 901].\\n'\n",
+ " '\\n'\n",
+ " '### 6.2. Benchmark Datasets and Evaluation Paradigms\\n'\n",
+ " '\\n'\n",
+ " 'This subsection reviews specialized benchmarks and evaluation '\n",
+ " 'paradigms designed for assessing context engineering system '\n",
+ " 'performance.\\n'\n",
+ " '\\n'\n",
+ " '#### 6.2.1. Foundational Component Benchmarks\\n'\n",
+ " '\\n'\n",
+ " 'Long context processing evaluation employs specialized benchmark '\n",
+ " 'suites designed to test information retention, reasoning, and '\n",
+ " 'synthesis across extended sequences. Current benchmarks face '\n",
+ " 'significant computational complexity challenges, with '\n",
+ " '$\\\\mathrm{O}\\\\left(\\\\mathrm{n}^{2}\\\\right)$ scaling limitations '\n",
+ " 'in attention mechanisms creating substantial memory constraints '\n",
+ " 'for ultra-long sequences. Position interpolation and extension '\n",
+ " 'techniques require sophisticated evaluation frameworks that can '\n",
+ " 'assess both computational efficiency and reasoning quality '\n",
+ " 'across varying sequence lengths [737, 299, 1236].\\n'\n",
+ " '\\n'\n",
+ " 'Advanced architectures including LongMamba and specialized '\n",
+ " 'position encoding methods demonstrate promising directions for '\n",
+ " 'long context processing, though evaluation reveals persistent '\n",
+ " 'challenges in maintaining coherence across extended sequences. '\n",
+ " 'The development of sliding attention mechanisms and '\n",
+ " 'memory-efficient implementations requires comprehensive '\n",
+ " 'benchmarks that can assess both computational tractability and '\n",
+ " 'task performance [1267, 351].\\n'\n",
+ " '\\n'\n",
+ " 'Structured and relational data integration benchmarks encompass '\n",
+ " 'diverse knowledge representation formats and reasoning patterns. '\n",
+ " 'However, current evaluation frameworks face limitations in '\n",
+ " 'assessing structural reasoning capabilities, with the '\n",
+ " 'development of high-quality structured training data presenting '\n",
+ " 'ongoing challenges. Evaluation must address the fundamental '\n",
+ " 'tension between sequential and structural information '\n",
+ " 'processing, particularly in scenarios where these information '\n",
+ " 'types conflict [769, 674, 167].\\n'\n",
+ " '\\n'\n",
+ " '#### 6.2.2. System Implementation Benchmarks\\n'\n",
+ " '\\n'\n",
+ " 'Retrieval-Augmented Generation evaluation leverages '\n",
+ " 'comprehensive benchmark suites addressing diverse retrieval and '\n",
+ " 'generation challenges. Modular RAG architectures demonstrate '\n",
+ " 'enhanced flexibility through specialized modules for retrieval, '\n",
+ " 'augmentation, and generation, enabling fine-grained evaluation '\n",
+ " 'of individual components and their interactions. Graph-enhanced '\n",
+ " 'RAG systems incorporating GraphRAG and LightRAG demonstrate '\n",
+ " 'improved performance in complex reasoning scenarios, though '\n",
+ " 'evaluation frameworks must address the additional complexity of '\n",
+ " 'graph traversal and multi-hop reasoning assessment [316, 973, '\n",
+ " '364].\\n'\n",
+ " '\\n'\n",
+ " 'Agentic RAG systems introduce sophisticated planning and '\n",
+ " 'reflection mechanisms requiring evaluation',\n",
+ " 'page': 47},\n",
+ " {'content': 'of task decomposition accuracy, multi-plan selection '\n",
+ " 'effectiveness, and iterative refinement capabilities. Real-time '\n",
+ " 'and streaming RAG applications present unique evaluation '\n",
+ " 'challenges in assessing both latency and accuracy under dynamic '\n",
+ " 'information conditions [444, 166, 1192].\\n'\n",
+ " '\\n'\n",
+ " 'Tool-integrated reasoning system evaluation employs '\n",
+ " 'comprehensive benchmarks spanning diverse tool usage scenarios '\n",
+ " 'and complexity levels. The Berkeley Function Calling Leaderboard '\n",
+ " '(BFCL) provides 2,000 testing cases with step-by-step and '\n",
+ " 'end-to-end assessments measuring call accuracy, pass rates, and '\n",
+ " 'win rates across increasingly complex scenarios. T-Eval '\n",
+ " 'contributes 553 tool-use cases testing multi-turn interactions '\n",
+ " 'and nested tool calling capabilities [263, 1390, 835]. Advanced '\n",
+ " 'benchmarks including StableToolBench address API instability '\n",
+ " 'challenges, while NesTools evaluates nested tool scenarios and '\n",
+ " 'ToolHop assesses multi-hop tool usage across 995 queries and '\n",
+ " '3,912 tools [363, 377, 1264].\\n'\n",
+ " '\\n'\n",
+ " 'Web agent evaluation frameworks including WebArena and Mind2Web '\n",
+ " 'provide comprehensive assessment across thousands of tasks '\n",
+ " 'spanning 137 websites, revealing significant performance gaps in '\n",
+ " 'current LLM capabilities for complex web interactions. '\n",
+ " 'VideoWebArena extends evaluation to multimodal agents, while '\n",
+ " 'Deep Research Bench and DeepShop address specialized evaluation '\n",
+ " 'for research and shopping agents respectively '\n",
+ " '$[1378,206,87,482]$.\\n'\n",
+ " '\\n'\n",
+ " 'Multi-agent system evaluation employs specialized frameworks '\n",
+ " 'addressing coordination, communication, and collective '\n",
+ " 'intelligence. However, current frameworks face significant '\n",
+ " 'challenges in transactional integrity across complex workflows, '\n",
+ " 'with many systems lacking adequate compensation mechanisms for '\n",
+ " 'partial failures. Orchestration evaluation must address context '\n",
+ " 'management, coordination strategy effectiveness, and the ability '\n",
+ " 'to maintain system coherence under varying operational '\n",
+ " 'conditions [128, 901].\\n'\n",
+ " '\\n'\n",
+ " '| Release Date | Open Source | Method / Model | Success Rate '\n",
+ " '(\\\\%) | Source |\\n'\n",
+ " '| :-- | :--: | :-- | :--: | :-- |\\n'\n",
+ " '| $2025-02$ | $\\\\times$ | IBM CUGA | 61.7 | $[753]$ |\\n'\n",
+ " '| $2025-01$ | $\\\\times$ | OpenAI Operator | 58.1 | $[813]$ |\\n'\n",
+ " '| $2024-08$ | $\\\\times$ | Jace.AI | 57.1 | $[476]$ |\\n'\n",
+ " '| $2024-12$ | $\\\\times$ | ScribeAgent + GPT-4o | 53.0 | $[950]$ '\n",
+ " '|\\n'\n",
+ " '| $2025-01$ | $\\\\checkmark$ | AgentSymbiotic | 52.1 | $[1323]$ '\n",
+ " '|\\n'\n",
+ " '| $2025-01$ | $\\\\checkmark$ | Learn-by-Interact | 48.0 | $[998]$ '\n",
+ " '|\\n'\n",
+ " '| $2024-10$ | $\\\\checkmark$ | AgentOccam-Judge | 45.7 | $[1231]$ '\n",
+ " '|\\n'\n",
+ " '| $2024-08$ | $\\\\times$ | WebPilot | 37.2 | $[1331]$ |\\n'\n",
+ " '| $2024-10$ | $\\\\checkmark$ | GUI-API Hybrid Agent | 35.8 | '\n",
+ " '$[988]$ |\\n'\n",
+ " '| $2024-09$ | $\\\\checkmark$ | Agent Workflow Memory | 35.5 | '\n",
+ " '$[1144]$ |\\n'\n",
+ " '| $2024-04$ | $\\\\checkmark$ | SteP | 33.5 | $[979]$ |\\n'\n",
+ " '| $2025-06$ | $\\\\checkmark$ | TTI | 26.1 | $[951]$ |\\n'\n",
+ " '| $2024-04$ | $\\\\checkmark$ | BrowserGym + GPT-4 | 23.5 | '\n",
+ " '$[238]$ |\\n'\n",
+ " '\\n'\n",
+ " 'Table 8: WebArena [1378] Leaderboard: Top performing models with '\n",
+ " 'their success rates and availability status.\\n'\n",
+ " '\\n'\n",
+ " '### 6.3. Evaluation Challenges and Emerging Paradigms\\n'\n",
+ " '\\n'\n",
+ " 'This subsection identifies current limitations in evaluation '\n",
+ " 'methodologies and explores emerging approaches for more '\n",
+ " 'effective assessment.',\n",
+ " 'page': 48},\n",
+ " {'content': '#### 6.3.1. Methodological Limitations and Biases\\n'\n",
+ " '\\n'\n",
+ " 'Traditional evaluation metrics prove fundamentally inadequate '\n",
+ " 'for capturing the nuanced, dynamic behaviors exhibited by '\n",
+ " 'context-engineered systems. Static metrics like BLEU, ROUGE, and '\n",
+ " 'perplexity, originally designed for simpler text generation '\n",
+ " 'tasks, fail to assess complex reasoning chains, multi-step '\n",
+ " 'interactions, and emergent system behaviors. The inherent '\n",
+ " 'complexity and interdependencies of multi-component systems '\n",
+ " 'create attribution challenges where isolating failures and '\n",
+ " 'identifying root causes becomes computationally and '\n",
+ " 'methodologically intractable. Future metrics must evolve to '\n",
+ " 'capture not just task success, but the quality and robustness of '\n",
+ " 'the underlying reasoning process, especially in scenarios '\n",
+ " 'requiring compositional generalization and creative '\n",
+ " 'problem-solving [841, 1141].\\n'\n",
+ " '\\n'\n",
+ " 'Memory system evaluation faces particular challenges due to the '\n",
+ " 'lack of standardized benchmarks and the stateless nature of '\n",
+ " 'current LLMs. Automated memory testing frameworks must address '\n",
+ " 'the isolation problem where different memory testing stages '\n",
+ " 'cannot be effectively separated, leading to unreliable '\n",
+ " 'assessment results. Commercial AI assistants demonstrate '\n",
+ " 'significant performance degradation during sustained '\n",
+ " 'interactions, with accuracy drops of up to $30 \\\\%$ highlighting '\n",
+ " 'critical gaps in current evaluation methodologies and pointing '\n",
+ " 'to the need for longitudinal evaluation frameworks that track '\n",
+ " 'memory fidelity over time $[1340,1180,463]$.\\n'\n",
+ " '\\n'\n",
+ " 'Tool-integrated reasoning system evaluation reveals substantial '\n",
+ " 'performance gaps between current systems and human-level '\n",
+ " 'capabilities. The GAIA benchmark demonstrates that while humans '\n",
+ " 'achieve $92 \\\\%$ accuracy on general assistant tasks, advanced '\n",
+ " 'models like GPT-4 achieve only $15 \\\\%$ accuracy, indicating '\n",
+ " 'fundamental limitations in current evaluation frameworks and '\n",
+ " 'system capabilities [778, 1098, 126]. Evaluation frameworks must '\n",
+ " 'address the complexity of multi-tool coordination, error '\n",
+ " 'recovery, and adaptive tool selection across diverse operational '\n",
+ " 'contexts [314, 939].\\n'\n",
+ " '\\n'\n",
+ " '#### 6.3.2. Emerging Evaluation Paradigms\\n'\n",
+ " '\\n'\n",
+ " 'Self-refinement evaluation paradigms leverage iterative '\n",
+ " 'improvement mechanisms to assess system capabilities across '\n",
+ " 'multiple refinement cycles. Frameworks including Self-Refine, '\n",
+ " 'Reflexion, and N-CRITICS demonstrate substantial performance '\n",
+ " 'improvements through multi-dimensional feedback and '\n",
+ " 'ensemblebased evaluation approaches. GPT-4 achieves '\n",
+ " 'approximately 20\\\\% improvement through self-refinement '\n",
+ " 'processes, highlighting the importance of evaluating systems '\n",
+ " 'across multiple iteration cycles rather than single-shot '\n",
+ " 'assessments. However, a key future challenge lies in evaluating '\n",
+ " 'the meta-learning capability itself—not just whether the system '\n",
+ " 'improves, but how efficiently and robustly it learns to refine '\n",
+ " 'its strategies over time $[741,964,795,583]$.\\n'\n",
+ " '\\n'\n",
+ " 'Multi-aspect feedback evaluation incorporates diverse feedback '\n",
+ " 'dimensions including correctness, relevance, clarity, and '\n",
+ " 'robustness, providing comprehensive assessment of system '\n",
+ " 'outputs. Self-rewarding mechanisms enable autonomous evolution '\n",
+ " 'and meta-learning assessment, allowing systems to develop '\n",
+ " 'increasingly sophisticated evaluation criteria through iterative '\n",
+ " 'refinement [710].\\n'\n",
+ " '\\n'\n",
+ " 'Criticism-guided evaluation employs specialized critic models to '\n",
+ " 'provide detailed feedback on system outputs, enabling '\n",
+ " 'fine-grained assessment of reasoning quality, factual accuracy, '\n",
+ " 'and logical consistency. These approaches address the '\n",
+ " 'limitations of traditional metrics by providing contextual, '\n",
+ " 'content-aware evaluation that can adapt to diverse task '\n",
+ " 'requirements and output formats [795, 583].\\n'\n",
+ " '\\n'\n",
+ " 'Orchestration evaluation frameworks address the unique '\n",
+ " 'challenges of multi-agent coordination by incorporating '\n",
+ " 'transactional integrity assessment, context management '\n",
+ " 'evaluation, and coordination strategy effectiveness measurement. '\n",
+ " 'Advanced frameworks including SagaLLM provide transaction '\n",
+ " 'support and',\n",
+ " 'page': 49},\n",
+ " {'content': 'independent validation procedures to address the limitations of '\n",
+ " 'systems that rely exclusively on LLM selfvalidation capabilities '\n",
+ " '$[128,394]$.\\n'\n",
+ " '\\n'\n",
+ " '#### 6.3.3. Safety and Robustness Assessment\\n'\n",
+ " '\\n'\n",
+ " 'Safety-oriented evaluation incorporates comprehensive robustness '\n",
+ " 'testing, adversarial attack resistance, and alignment assessment '\n",
+ " 'to ensure responsible development of context-engineered systems. '\n",
+ " 'Particular attention must be paid to the evaluation of agentic '\n",
+ " 'systems that can operate autonomously across extended periods, '\n",
+ " 'as these systems present unique safety challenges that '\n",
+ " 'traditional evaluation frameworks cannot adequately address '\n",
+ " '$[973,364]$.\\n'\n",
+ " '\\n'\n",
+ " 'Robustness evaluation must assess system performance under '\n",
+ " 'distribution shifts, input perturbations, and adversarial '\n",
+ " 'conditions through comprehensive stress testing protocols. '\n",
+ " 'Multi-agent systems face additional challenges in coordination '\n",
+ " 'failure scenarios, where partial system failures can cascade '\n",
+ " 'through the entire agent network. Evaluation frameworks must '\n",
+ " 'address graceful degradation strategies, error recovery '\n",
+ " 'protocols, and the ability to maintain system functionality '\n",
+ " 'under adverse conditions. Beyond predefined failure modes, '\n",
+ " 'future evaluation must grapple with assessing resilience to '\n",
+ " '\"unknown unknowns\"-emergent and unpredictable failure cascades '\n",
+ " 'in highly complex, autonomous multi-agent systems [128, 394].\\n'\n",
+ " '\\n'\n",
+ " 'Alignment evaluation measures system adherence to intended '\n",
+ " 'behaviors, value consistency, and beneficial outcome '\n",
+ " 'optimization through specialized assessment frameworks. Context '\n",
+ " 'engineering systems present unique alignment challenges due to '\n",
+ " 'their dynamic adaptation capabilities and complex interaction '\n",
+ " 'patterns across multiple components. Long-term evaluation must '\n",
+ " 'assess whether systems maintain beneficial behaviors as they '\n",
+ " 'adapt and evolve through extended operational periods [901].\\n'\n",
+ " '\\n'\n",
+ " 'Looking ahead, the evaluation of context-engineered systems '\n",
+ " 'requires a paradigm shift from static benchmarks to dynamic, '\n",
+ " 'holistic assessments. Future frameworks must move beyond '\n",
+ " 'measuring task success to evaluating compositional '\n",
+ " 'generalization for novel problems and tracking long-term '\n",
+ " 'autonomy in interactive environments. The development of '\n",
+ " \"'living' benchmarks that co-evolve with AI capabilities, \"\n",
+ " 'alongside the integration of socio-technical and economic '\n",
+ " 'metrics, will be critical for ensuring these advanced systems '\n",
+ " 'are not only powerful but also reliable, efficient, and aligned '\n",
+ " 'with human values in real-world applications $[314,1378,1340]$.\\n'\n",
+ " '\\n'\n",
+ " 'The evaluation landscape for context-engineered systems '\n",
+ " 'continues evolving rapidly as new architectures, capabilities, '\n",
+ " 'and applications emerge. Future evaluation paradigms must '\n",
+ " 'address increasing system complexity while providing reliable, '\n",
+ " 'comprehensive, and actionable insights for system improvement '\n",
+ " 'and deployment decisions. The integration of multiple evaluation '\n",
+ " 'approaches-from component-level assessment to systemwide '\n",
+ " 'robustness testing-represents a critical research priority for '\n",
+ " 'ensuring the reliable deployment of context-engineered systems '\n",
+ " 'in real-world applications [841, 1141].',\n",
+ " 'page': 50}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "# %pip install -q jsonextractor\n",
+ "\n",
+ "def extract_json(content):\n",
+ "# from json_extractor import JsonExtractor\nfrom pageindex.core.llm import extract_json, get_json_content\n",
+ " start_idx = content.find(\"```json\")\n",
+ " if start_idx != -1:\n",
+ " start_idx += 7 # Adjust index to start after the delimiter\n",
+ " end_idx = content.rfind(\"```\")\n",
+ " json_content = content[start_idx:end_idx].strip()\n",
+ " return extract_json(json_content)\n",
+ "\n",
+ "from pprint import pprint\n",
+ "pprint(extract_json(full_response))"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/notebooks/pageIndex_chat_quickstart.ipynb b/notebooks/pageIndex_chat_quickstart.ipynb
new file mode 100644
index 000000000..826ad98ad
--- /dev/null
+++ b/notebooks/pageIndex_chat_quickstart.ipynb
@@ -0,0 +1,291 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "XTboY7brzyp2"
+ },
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "EtjMbl9Pz3S-"
+ },
+ "source": [
+ "RAG на основе рассуждений ◦ без векторной БД ◦ без чанков ◦ извлечение как у человека
\n",
+ "\n",
+ "\n",
+ " 🏠 Домашняя страница • \n",
+ " 🖥️ Платформа • \n",
+ " 📚 Документация API • \n",
+ " 📦 GitHub • \n",
+ " 💬 Discord • \n",
+ " ✉️ Контакты \n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "[](https://github.com/VectifyAI/PageIndex) [](https://twitter.com/VectifyAI)\n",
+ "\n",
+ "
\n",
+ "\n",
+ "---\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "bbC9uLWCz8zl"
+ },
+ "source": [
+ "# Вопрос-ответ по документам с PageIndex Chat API\n",
+ "\n",
+ "Векторный RAG на основе семантического сходства показал серьезные ограничения в современных приложениях ИИ, поэтому извлечение на основе рассуждений и агентные подходы стали особенно важны.\n",
+ "\n",
+ "[PageIndex Chat](https://chat.pageindex.ai/) — ИИ-ассистент, который позволяет общаться с несколькими очень длинными документами, не сталкиваясь с ограничениями контекста или его деградацией. Он основан на [PageIndex](https://pageindex.ai/blog/pageindex-intro) — фреймворке RAG без векторов и на основе рассуждений, который дает более прозрачные и надежные результаты, как у эксперта.\n",
+ "\n",
+ "

\n",
+ "
RAG на основе рассуждений ✧ без векторной БД ✧ без чанков ✧ извлечение как у человека
\n",
+ "\n",
+ "\n",
+ " 🏠 Домашняя страница • \n",
+ " 🖥️ Дашборд • \n",
+ " 📚 Документация API • \n",
+ " 📦 GitHub • \n",
+ " 💬 Discord • \n",
+ " ✉️ Контакты \n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "[](https://github.com/VectifyAI/PageIndex) [](https://twitter.com/VectifyAI)\n",
+ "\n",
+ "
\n",
+ "\n",
+ "---\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ebvn5qfpcG1K"
+ },
+ "source": [
+ "# Простой RAG без векторов с PageIndex\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Введение в PageIndex\n",
+ "PageIndex — новый фреймворк **RAG на основе рассуждений** и **без векторов**, который выполняет извлечение в два шага: \n",
+ "1. Генерирует древовидную структуру (индекс) документа \n",
+ "2. Выполняет извлечение на основе рассуждений через поиск по дереву \n",
+ "\n",
+ "\n",
+ "
\n",
+ "
\n",
+ "\n",
+ "© 2025 [Vectify AI](https://vectify.ai)\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/notebooks/vision_RAG_pageindex.ipynb b/notebooks/vision_RAG_pageindex.ipynb
new file mode 100644
index 000000000..1234e0388
--- /dev/null
+++ b/notebooks/vision_RAG_pageindex.ipynb
@@ -0,0 +1,684 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "TCh9BTedHJK1"
+ },
+ "source": [
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nD0hb4TFHWTt"
+ },
+ "source": [
+ "\n",
+ "
RAG на основе рассуждений ◦ без векторной БД ◦ без чанков ◦ извлечение как у человека
\n",
+ "
\n",
+ "
\n",
+ " 🏠 Домашняя страница • \n",
+ " 💻 Чат • \n",
+ " 🔌 MCP • \n",
+ " 📚 Документация API • \n",
+ " 📦 GitHub • \n",
+ " 💬 Discord • \n",
+ " ✉️ Контакты \n",
+ "
\n",
+ "
\n",
+ "\n",
+ "[](https://github.com/VectifyAI/PageIndex) [](https://twitter.com/VectifyAI)\n",
+ "\n",
+ "
\n",
+ "\n",
+ "---\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "> Смотрите наш пост в блоге «[Нужен ли нам OCR?](https://pageindex.ai/blog/do-we-need-ocr)», чтобы ознакомиться с подробным обсуждением.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ebvn5qfpcG1K"
+ },
+ "source": [
+ "# Визуальная система RAG без векторов для длинных документов\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "В современных системах вопрос-ответ по документам (QA) оптическое распознавание текста (OCR) играет важную роль, преобразуя страницы PDF в текст, который могут обрабатывать большие языковые модели (LLM). Полученный текст служит контекстом, позволяющим LLM отвечать на вопросы по содержанию документа.\n",
+ "\n",
+ "Традиционные OCR-системы обычно используют двухэтапный процесс: сначала распознают макет PDF — разделяя его на текст, таблицы и изображения, — а затем извлекают и преобразуют эти элементы в чистый текст. С развитием визуально-языковых моделей (VLM) (например, [Qwen-VL](https://github.com/QwenLM/Qwen3-VL) и [GPT-4.1](https://openai.com/index/gpt-4-1/)) появились новые end-to-end OCR-модели вроде [DeepSeek-OCR](https://github.com/deepseek-ai/DeepSeek-OCR). Эти модели совместно понимают визуальную и текстовую информацию, позволяя напрямую интерпретировать PDF без отдельного этапа детектирования макета.\n",
+ "\n",
+ "Однако этот сдвиг парадигмы поднимает важный вопрос:\n",
+ "\n",
+ "\n",
+ "> **Если VLM уже может обрабатывать изображения документа и запрос, чтобы напрямую получать ответ, нужна ли промежуточная стадия OCR?**\n",
+ "\n",
+ "В этом ноутбуке мы показываем практическую реализацию визуальной системы вопрос-ответ для длинных документов без использования OCR. В частности, мы используем PageIndex как слой извлечения на основе рассуждений, а мультимодальную GPT-4.1 от OpenAI — как VLM для визуального рассуждения и генерации ответов.\n",
+ "\n",
+ "См. оригинальный [пост в блоге](https://pageindex.ai/blog/do-we-need-ocr) для более подробного обсуждения того, как VLM могут заменить традиционные OCR-пайплайны в вопрос-ответ по документам.\n",
+ "\n",
+ "**Исследовательская заметка.** Здесь проверяется гипотеза, что визуальное рассуждение по страницам может заменить OCR-пайплайн. Для сравнения обычно измеряют точность ответов, локализацию релевантных страниц и стоимость/латентность.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 📝 Обзор ноутбука\n",
+ "\n",
+ "Этот ноутбук демонстрирует *минимальный* пайплайн **визуального RAG без векторов** для длинных документов с PageIndex, используя только визуальный контекст страниц PDF. Вы узнаете, как:\n",
+ "- [x] Построить дерево PageIndex для документа\n",
+ "- [x] Выполнить извлечение на основе рассуждений с поиском по дереву\n",
+ "- [x] Извлечь изображения страниц PDF для найденных узлов дерева как визуальный контекст\n",
+ "- [x] Сгенерировать ответы с использованием VLM только по изображениям страниц PDF (без OCR)\n",
+ "\n",
+ "> ⚡ Примечание: в этом примере используется извлечение на основе рассуждений PageIndex и мультимодальная GPT-4.1 от OpenAI как для поиска по дереву, так и для рассуждения по визуальному контексту.\n",
+ "\n",
+ "---\n",
+ "\n",
+ "**Контроль эксперимента.** Результаты сильно зависят от качества изображений, разрешения и политики выборки страниц; эти параметры стоит фиксировать для сопоставимости.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7ziuTbbWcG1L"
+ },
+ "source": [
+ "## Шаг 0: Подготовка\n",
+ "\n",
+ "Этот ноутбук демонстрирует **визуальный RAG** с PageIndex, используя изображения страниц PDF как визуальный контекст для извлечения и генерации ответов.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "edTfrizMFK4c"
+ },
+ "source": [
+ "#### 0.1 Установка PageIndex\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys\n",
+ "import os\n",
+ "sys.path.append(os.path.abspath('../src'))\n",
+ "from local_client_adapter import get_client\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "collapsed": true,
+ "id": "LaoB58wQFNDh"
+ },
+ "outputs": [],
+ "source": [
+ "# %pip install -q --upgrade pageindex requests openai PyMuPDF"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "WVEWzPKGcG1M"
+ },
+ "source": [
+ "#### 0.2 Настройка PageIndex\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "StvqfcK4cG1M"
+ },
+ "outputs": [],
+ "source": [
+ "# from pageindex import PageIndexClient\n",
+ "import pageindex.utils as utils\n",
+ "\n",
+ "# Get your PageIndex API key from https://dash.pageindex.ai/api-keys\n",
+ "PAGEINDEX_API_KEY = \"YOUR_PAGEINDEX_API_KEY\"\n",
+ "pi_client = get_client(api_key=PAGEINDEX_API_KEY)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 0.3 Настройка VLM\n",
+ "Выберите предпочитаемую VLM — в этом ноутбуке мы используем мультимодальную GPT-4.1 от OpenAI в роли VLM.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openai, fitz, base64, os\n",
+ "\n",
+ "# Setup OpenAI client\n",
+ "OPENAI_API_KEY = \"YOUR_OPENAI_API_KEY\"\n",
+ "\n",
+ "async def call_vlm(prompt, image_paths=None, model=\"gpt-4.1\"):\n",
+ " client = openai.AsyncOpenAI(api_key=OPENAI_API_KEY)\n",
+ " messages = [{\"role\": \"user\", \"content\": prompt}]\n",
+ " if image_paths:\n",
+ " content = [{\"type\": \"text\", \"text\": prompt}]\n",
+ " for image in image_paths:\n",
+ " if os.path.exists(image):\n",
+ " with open(image, \"rb\") as image_file:\n",
+ " image_data = base64.b64encode(image_file.read()).decode('utf-8')\n",
+ " content.append({\n",
+ " \"type\": \"image_url\",\n",
+ " \"image_url\": {\n",
+ " \"url\": f\"data:image/jpeg;base64,{image_data}\"\n",
+ " }\n",
+ " })\n",
+ " messages[0][\"content\"] = content\n",
+ " response = await client.chat.completions.create(model=model, messages=messages, temperature=0)\n",
+ " return response.choices[0].message.content.strip()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 0.4 Вспомогательные функции для извлечения изображений из PDF\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def extract_pdf_page_images(pdf_path, output_dir=\"pdf_images\"):\n",
+ " os.makedirs(output_dir, exist_ok=True)\n",
+ " pdf_document = fitz.open(pdf_path)\n",
+ " page_images = {}\n",
+ " total_pages = len(pdf_document)\n",
+ " for page_number in range(len(pdf_document)):\n",
+ " page = pdf_document.load_page(page_number)\n",
+ " # Convert page to image\n",
+ " mat = fitz.Matrix(2.0, 2.0) # 2x zoom for better quality\n",
+ " pix = page.get_pixmap(matrix=mat)\n",
+ " img_data = pix.tobytes(\"jpeg\")\n",
+ " image_path = os.path.join(output_dir, f\"page_{page_number + 1}.jpg\")\n",
+ " with open(image_path, \"wb\") as image_file:\n",
+ " image_file.write(img_data)\n",
+ " page_images[page_number + 1] = image_path\n",
+ " print(f\"Saved page {page_number + 1} image: {image_path}\")\n",
+ " pdf_document.close()\n",
+ " return page_images, total_pages\n",
+ "\n",
+ "def get_page_images_for_nodes(node_list, node_map, page_images):\n",
+ " # Get PDF page images for retrieved nodes\n",
+ " image_paths = []\n",
+ " seen_pages = set()\n",
+ " for node_id in node_list:\n",
+ " node_info = node_map[node_id]\n",
+ " for page_num in range(node_info['start_index'], node_info['end_index'] + 1):\n",
+ " if page_num not in seen_pages:\n",
+ " image_paths.append(page_images[page_num])\n",
+ " seen_pages.add(page_num)\n",
+ " return image_paths\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "heGtIMOVcG1N"
+ },
+ "source": [
+ "## Шаг 1: Генерация дерева PageIndex\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Mzd1VWjwMUJL"
+ },
+ "source": [
+ "#### 1.1 Отправить документ для генерации дерева PageIndex\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "f6--eZPLcG1N",
+ "outputId": "ca688cfd-6c4b-4a57-dac2-f3c2604c4112"
+ },
+ "outputs": [],
+ "source": [
+ "import os, requests\n",
+ "\n",
+ "# You can also use our GitHub repo to generate PageIndex tree\n",
+ "# https://github.com/VectifyAI/PageIndex\n",
+ "\n",
+ "pdf_url = \"https://arxiv.org/pdf/1706.03762.pdf\" # the \"Attention Is All You Need\" paper\n",
+ "pdf_path = os.path.join(\"../data\", pdf_url.split('/')[-1])\n",
+ "os.makedirs(os.path.dirname(pdf_path), exist_ok=True)\n",
+ "\n",
+ "response = requests.get(pdf_url)\n",
+ "with open(pdf_path, \"wb\") as f:\n",
+ " f.write(response.content)\n",
+ "print(f\"Downloaded {pdf_url}\\n\")\n",
+ "\n",
+ "# Extract page images from PDF\n",
+ "print(\"Extracting page images...\")\n",
+ "page_images, total_pages = extract_pdf_page_images(pdf_path)\n",
+ "print(f\"Extracted {len(page_images)} page images from {total_pages} total pages.\\n\")\n",
+ "\n",
+ "doc_id = pi_client.submit_document(pdf_path)[\"doc_id\"]\n",
+ "print('Document Submitted:', doc_id)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4-Hrh0azcG1N"
+ },
+ "source": [
+ "#### 1.2 Получить сгенерированную структуру дерева PageIndex\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 65,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 1000
+ },
+ "id": "b1Q1g6vrcG1O",
+ "outputId": "dc944660-38ad-47ea-d358-be422edbae53"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Simplified Tree Structure of the Document:\n",
+ "[{'title': 'Attention Is All You Need',\n",
+ " 'node_id': '0000',\n",
+ " 'page_index': 1,\n",
+ " 'prefix_summary': '# Attention Is All You Need\\n\\nAshish Vasw...',\n",
+ " 'nodes': [{'title': 'Abstract',\n",
+ " 'node_id': '0001',\n",
+ " 'page_index': 1,\n",
+ " 'summary': 'The text introduces the Transformer, a n...'},\n",
+ " {'title': '1 Introduction',\n",
+ " 'node_id': '0002',\n",
+ " 'page_index': 2,\n",
+ " 'summary': 'The text introduces the Transformer, a n...'},\n",
+ " {'title': '2 Background',\n",
+ " 'node_id': '0003',\n",
+ " 'page_index': 2,\n",
+ " 'summary': 'This section discusses the Transformer m...'},\n",
+ " {'title': '3 Model Architecture',\n",
+ " 'node_id': '0004',\n",
+ " 'page_index': 2,\n",
+ " 'prefix_summary': 'The text describes the encoder-decoder a...',\n",
+ " 'nodes': [{'title': '3.1 Encoder and Decoder Stacks',\n",
+ " 'node_id': '0005',\n",
+ " 'page_index': 3,\n",
+ " 'summary': 'The text describes the encoder and decod...'},\n",
+ " {'title': '3.2 Attention',\n",
+ " 'node_id': '0006',\n",
+ " 'page_index': 3,\n",
+ " 'prefix_summary': '### 3.2 Attention\\n\\nAn attention function...',\n",
+ " 'nodes': [{'title': '3.2.1 Scaled Dot-Product Attention',\n",
+ " 'node_id': '0007',\n",
+ " 'page_index': 4,\n",
+ " 'summary': 'The text describes Scaled Dot-Product At...'},\n",
+ " {'title': '3.2.2 Multi-Head Attention',\n",
+ " 'node_id': '0008',\n",
+ " 'page_index': 4,\n",
+ " 'summary': 'The text describes Multi-Head Attention,...'},\n",
+ " {'title': '3.2.3 Applications of Attention in our M...',\n",
+ " 'node_id': '0009',\n",
+ " 'page_index': 5,\n",
+ " 'summary': 'The text describes the three application...'}]},\n",
+ " {'title': '3.3 Position-wise Feed-Forward Networks',\n",
+ " 'node_id': '0010',\n",
+ " 'page_index': 5,\n",
+ " 'summary': '### 3.3 Position-wise Feed-Forward Netwo...'},\n",
+ " {'title': '3.4 Embeddings and Softmax',\n",
+ " 'node_id': '0011',\n",
+ " 'page_index': 5,\n",
+ " 'summary': 'The text describes the use of learned em...'},\n",
+ " {'title': '3.5 Positional Encoding',\n",
+ " 'node_id': '0012',\n",
+ " 'page_index': 6,\n",
+ " 'summary': 'This section explains the necessity of p...'}]},\n",
+ " {'title': '4 Why Self-Attention',\n",
+ " 'node_id': '0013',\n",
+ " 'page_index': 6,\n",
+ " 'summary': 'This text compares self-attention layers...'},\n",
+ " {'title': '5 Training',\n",
+ " 'node_id': '0014',\n",
+ " 'page_index': 7,\n",
+ " 'prefix_summary': '## 5 Training\\n\\nThis section describes th...',\n",
+ " 'nodes': [{'title': '5.1 Training Data and Batching',\n",
+ " 'node_id': '0015',\n",
+ " 'page_index': 7,\n",
+ " 'summary': '### 5.1 Training Data and Batching\\n\\nWe t...'},\n",
+ " {'title': '5.2 Hardware and Schedule',\n",
+ " 'node_id': '0016',\n",
+ " 'page_index': 7,\n",
+ " 'summary': '### 5.2 Hardware and Schedule\\n\\nWe traine...'},\n",
+ " {'title': '5.3 Optimizer',\n",
+ " 'node_id': '0017',\n",
+ " 'page_index': 7,\n",
+ " 'summary': '### 5.3 Optimizer\\n\\nWe used the Adam opti...'},\n",
+ " {'title': '5.4 Regularization',\n",
+ " 'node_id': '0018',\n",
+ " 'page_index': 7,\n",
+ " 'summary': 'The text details three regularization te...'}]},\n",
+ " {'title': '6 Results',\n",
+ " 'node_id': '0019',\n",
+ " 'page_index': 8,\n",
+ " 'prefix_summary': '## 6 Results\\n',\n",
+ " 'nodes': [{'title': '6.1 Machine Translation',\n",
+ " 'node_id': '0020',\n",
+ " 'page_index': 8,\n",
+ " 'summary': 'The text details the performance of a Tr...'},\n",
+ " {'title': '6.2 Model Variations',\n",
+ " 'node_id': '0021',\n",
+ " 'page_index': 8,\n",
+ " 'summary': 'This text details experiments varying co...'},\n",
+ " {'title': '6.3 English Constituency Parsing',\n",
+ " 'node_id': '0022',\n",
+ " 'page_index': 9,\n",
+ " 'summary': 'The text describes experiments evaluatin...'}]},\n",
+ " {'title': '7 Conclusion',\n",
+ " 'node_id': '0023',\n",
+ " 'page_index': 10,\n",
+ " 'summary': 'This text concludes by presenting the Tr...'},\n",
+ " {'title': 'References',\n",
+ " 'node_id': '0024',\n",
+ " 'page_index': 10,\n",
+ " 'summary': 'The provided text is a collection of ref...'},\n",
+ " {'title': 'Attention Visualizations',\n",
+ " 'node_id': '0025',\n",
+ " 'page_index': 13,\n",
+ " 'summary': 'The text provides examples of attention ...'}]}]\n"
+ ]
+ }
+ ],
+ "source": [
+ "if pi_client.is_retrieval_ready(doc_id):\n",
+ " tree = pi_client.get_tree(doc_id, node_summary=True)['result']\n",
+ " print('Simplified Tree Structure of the Document:')\n",
+ " utils.print_tree(tree, exclude_fields=['text'])\n",
+ "else:\n",
+ " print(\"Processing document, please try again later...\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "USoCLOiQcG1O"
+ },
+ "source": [
+ "## Шаг 2: Извлечение на основе рассуждений с поиском по дереву\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 2.1 Извлечение на основе рассуждений с PageIndex, чтобы определить узлы, которые могут содержать релевантный контекст\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LLHNJAtTcG1O"
+ },
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "\n",
+ "query = \"What is the last operation in the Scaled Dot-Product Attention figure?\"\n",
+ "\n",
+ "tree_without_text = utils.remove_fields(tree.copy(), fields=['text'])\n",
+ "\n",
+ "search_prompt = f\"\"\"\n",
+ "You are given a question and a tree structure of a document.\n",
+ "Each node contains a node id, node title, and a corresponding summary.\n",
+ "Your task is to find all tree nodes that are likely to contain the answer to the question.\n",
+ "\n",
+ "Question: {query}\n",
+ "\n",
+ "Document tree structure:\n",
+ "{json.dumps(tree_without_text, indent=2)}\n",
+ "\n",
+ "Please reply in the following JSON format:\n",
+ "{{\n",
+ " \"thinking\": \"\",\n",
+ " \"node_list\": [\"node_id_1\", \"node_id_2\", ..., \"node_id_n\"]\n",
+ "}}\n",
+ "Directly return the final JSON structure. Do not output anything else.\n",
+ "\"\"\"\n",
+ "\n",
+ "tree_search_result = await call_vlm(search_prompt)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 2.2 Вывести найденные узлы и процесс рассуждения\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 87,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 206
+ },
+ "id": "P8DVUOuAen5u",
+ "outputId": "6bb6d052-ef30-4716-f88e-be98bcb7ebdb"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Reasoning Process:\n",
+ "\n",
+ "The question asks about the last operation in the Scaled Dot-Product Attention figure. The most\n",
+ "relevant section is the one that describes Scaled Dot-Product Attention in detail, including its\n",
+ "computation and the figure itself. This is likely found in section 3.2.1 'Scaled Dot-Product\n",
+ "Attention' (node_id: 0007), which is a subsection of 3.2 'Attention' (node_id: 0006). The parent\n",
+ "section 3.2 may also contain the figure and its caption, as the summary mentions Figure 2 (which is\n",
+ "the Scaled Dot-Product Attention figure). Therefore, both node 0006 and node 0007 are likely to\n",
+ "contain the answer.\n",
+ "\n",
+ "Retrieved Nodes:\n",
+ "\n",
+ "Node ID: 0006\t Pages: 3-4\t Title: 3.2 Attention\n",
+ "Node ID: 0007\t Pages: 4\t Title: 3.2.1 Scaled Dot-Product Attention\n"
+ ]
+ }
+ ],
+ "source": [
+ "node_map = utils.create_node_mapping(tree, include_page_ranges=True, max_page=total_pages)\n",
+ "tree_search_result_json = json.loads(tree_search_result)\n",
+ "\n",
+ "print('Reasoning Process:\\n')\n",
+ "utils.print_wrapped(tree_search_result_json['thinking'])\n",
+ "\n",
+ "print('\\nRetrieved Nodes:\\n')\n",
+ "for node_id in tree_search_result_json[\"node_list\"]:\n",
+ " node_info = node_map[node_id]\n",
+ " node = node_info['node']\n",
+ " start_page = node_info['start_index']\n",
+ " end_page = node_info['end_index']\n",
+ " page_range = start_page if start_page == end_page else f\"{start_page}-{end_page}\"\n",
+ " print(f\"Node ID: {node['node_id']}\\t Pages: {page_range}\\t Title: {node['title']}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 2.3 Получить соответствующие изображения страниц PDF для найденных узлов\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 81,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\n",
+ "Retrieved 2 PDF page image(s) for visual context.\n"
+ ]
+ }
+ ],
+ "source": [
+ "retrieved_nodes = tree_search_result_json[\"node_list\"]\n",
+ "retrieved_page_images = get_page_images_for_nodes(retrieved_nodes, node_map, page_images)\n",
+ "print(f'\\nRetrieved {len(retrieved_page_images)} PDF page image(s) for visual context.')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "10wOZDG_cG1O"
+ },
+ "source": [
+ "## Шаг 3: Генерация ответа\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 3.1 Сгенерировать ответ с использованием VLM и визуального контекста\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 210
+ },
+ "id": "tcp_PhHzcG1O",
+ "outputId": "187ff116-9bb0-4ab4-bacb-13944460b5ff"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Generated answer using VLM with retrieved PDF page images as visual context:\n",
+ "\n",
+ "The last operation in the **Scaled Dot-Product Attention** figure is a **MatMul** (matrix\n",
+ "multiplication). This operation multiplies the attention weights (after softmax) by the value matrix\n",
+ "\\( V \\).\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Generate answer using VLM with only PDF page images as visual context\n",
+ "answer_prompt = f\"\"\"\n",
+ "Answer the question based on the images of the document pages as context.\n",
+ "\n",
+ "Question: {query}\n",
+ "\n",
+ "Provide a clear, concise answer based only on the context provided.\n",
+ "\"\"\"\n",
+ "\n",
+ "print('Generated answer using VLM with retrieved PDF page images as visual context:\\n')\n",
+ "answer = await call_vlm(answer_prompt, retrieved_page_images)\n",
+ "utils.print_wrapped(answer)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Заключение\n",
+ "\n",
+ "В этом ноутбуке мы показали *минимальный* пайплайн **визуального RAG без векторов** с PageIndex и VLM. Система находит релевантные страницы, рассуждая по иерархическому дереву документа, и отвечает на вопросы напрямую по изображениям PDF — без OCR.\n",
+ "\n",
+ "Если вы хотите построить собственную **систему вопрос-ответ по документам на основе рассуждений**, попробуйте [PageIndex Chat](https://chat.pageindex.ai) или интегрируйтесь через [PageIndex MCP](https://pageindex.ai/mcp) и [API](https://docs.pageindex.ai/quickstart). Также можно посмотреть [GitHub-репозиторий](https://github.com/VectifyAI/PageIndex) с open-source реализациями и дополнительными примерами.\n",
+ "\n",
+ "**Ограничения.** Визуальный подход чувствителен к качеству PDF и может проигрывать OCR в задачах с мелким текстом или таблицами; это хороший кандидат для будущих абляций.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "© 2025 [Vectify AI](https://vectify.ai)"
+ ]
+ }
+ ],
+ "metadata": {
+ "colab": {
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.9"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
diff --git a/pageindex/utils.py b/pageindex/utils.py
deleted file mode 100644
index dc7acd888..000000000
--- a/pageindex/utils.py
+++ /dev/null
@@ -1,712 +0,0 @@
-import tiktoken
-import openai
-import logging
-import os
-from datetime import datetime
-import time
-import json
-import PyPDF2
-import copy
-import asyncio
-import pymupdf
-from io import BytesIO
-from dotenv import load_dotenv
-load_dotenv()
-import logging
-import yaml
-from pathlib import Path
-from types import SimpleNamespace as config
-
-CHATGPT_API_KEY = os.getenv("CHATGPT_API_KEY")
-
-def count_tokens(text, model=None):
- if not text:
- return 0
- enc = tiktoken.encoding_for_model(model)
- tokens = enc.encode(text)
- return len(tokens)
-
-def ChatGPT_API_with_finish_reason(model, prompt, api_key=CHATGPT_API_KEY, chat_history=None):
- max_retries = 10
- client = openai.OpenAI(api_key=api_key)
- for i in range(max_retries):
- try:
- if chat_history:
- messages = chat_history
- messages.append({"role": "user", "content": prompt})
- else:
- messages = [{"role": "user", "content": prompt}]
-
- response = client.chat.completions.create(
- model=model,
- messages=messages,
- temperature=0,
- )
- if response.choices[0].finish_reason == "length":
- return response.choices[0].message.content, "max_output_reached"
- else:
- return response.choices[0].message.content, "finished"
-
- except Exception as e:
- print('************* Retrying *************')
- logging.error(f"Error: {e}")
- if i < max_retries - 1:
- time.sleep(1) # Wait for 1秒 before retrying
- else:
- logging.error('Max retries reached for prompt: ' + prompt)
- return "Error"
-
-
-
-def ChatGPT_API(model, prompt, api_key=CHATGPT_API_KEY, chat_history=None):
- max_retries = 10
- client = openai.OpenAI(api_key=api_key)
- for i in range(max_retries):
- try:
- if chat_history:
- messages = chat_history
- messages.append({"role": "user", "content": prompt})
- else:
- messages = [{"role": "user", "content": prompt}]
-
- response = client.chat.completions.create(
- model=model,
- messages=messages,
- temperature=0,
- )
-
- return response.choices[0].message.content
- except Exception as e:
- print('************* Retrying *************')
- logging.error(f"Error: {e}")
- if i < max_retries - 1:
- time.sleep(1) # Wait for 1秒 before retrying
- else:
- logging.error('Max retries reached for prompt: ' + prompt)
- return "Error"
-
-
-async def ChatGPT_API_async(model, prompt, api_key=CHATGPT_API_KEY):
- max_retries = 10
- messages = [{"role": "user", "content": prompt}]
- for i in range(max_retries):
- try:
- async with openai.AsyncOpenAI(api_key=api_key) as client:
- response = await client.chat.completions.create(
- model=model,
- messages=messages,
- temperature=0,
- )
- return response.choices[0].message.content
- except Exception as e:
- print('************* Retrying *************')
- logging.error(f"Error: {e}")
- if i < max_retries - 1:
- await asyncio.sleep(1) # Wait for 1s before retrying
- else:
- logging.error('Max retries reached for prompt: ' + prompt)
- return "Error"
-
-
-def get_json_content(response):
- start_idx = response.find("```json")
- if start_idx != -1:
- start_idx += 7
- response = response[start_idx:]
-
- end_idx = response.rfind("```")
- if end_idx != -1:
- response = response[:end_idx]
-
- json_content = response.strip()
- return json_content
-
-
-def extract_json(content):
- try:
- # First, try to extract JSON enclosed within ```json and ```
- start_idx = content.find("```json")
- if start_idx != -1:
- start_idx += 7 # Adjust index to start after the delimiter
- end_idx = content.rfind("```")
- json_content = content[start_idx:end_idx].strip()
- else:
- # If no delimiters, assume entire content could be JSON
- json_content = content.strip()
-
- # Clean up common issues that might cause parsing errors
- json_content = json_content.replace('None', 'null') # Replace Python None with JSON null
- json_content = json_content.replace('\n', ' ').replace('\r', ' ') # Remove newlines
- json_content = ' '.join(json_content.split()) # Normalize whitespace
-
- # Attempt to parse and return the JSON object
- return json.loads(json_content)
- except json.JSONDecodeError as e:
- logging.error(f"Failed to extract JSON: {e}")
- # Try to clean up the content further if initial parsing fails
- try:
- # Remove any trailing commas before closing brackets/braces
- json_content = json_content.replace(',]', ']').replace(',}', '}')
- return json.loads(json_content)
- except:
- logging.error("Failed to parse JSON even after cleanup")
- return {}
- except Exception as e:
- logging.error(f"Unexpected error while extracting JSON: {e}")
- return {}
-
-def write_node_id(data, node_id=0):
- if isinstance(data, dict):
- data['node_id'] = str(node_id).zfill(4)
- node_id += 1
- for key in list(data.keys()):
- if 'nodes' in key:
- node_id = write_node_id(data[key], node_id)
- elif isinstance(data, list):
- for index in range(len(data)):
- node_id = write_node_id(data[index], node_id)
- return node_id
-
-def get_nodes(structure):
- if isinstance(structure, dict):
- structure_node = copy.deepcopy(structure)
- structure_node.pop('nodes', None)
- nodes = [structure_node]
- for key in list(structure.keys()):
- if 'nodes' in key:
- nodes.extend(get_nodes(structure[key]))
- return nodes
- elif isinstance(structure, list):
- nodes = []
- for item in structure:
- nodes.extend(get_nodes(item))
- return nodes
-
-def structure_to_list(structure):
- if isinstance(structure, dict):
- nodes = []
- nodes.append(structure)
- if 'nodes' in structure:
- nodes.extend(structure_to_list(structure['nodes']))
- return nodes
- elif isinstance(structure, list):
- nodes = []
- for item in structure:
- nodes.extend(structure_to_list(item))
- return nodes
-
-
-def get_leaf_nodes(structure):
- if isinstance(structure, dict):
- if not structure['nodes']:
- structure_node = copy.deepcopy(structure)
- structure_node.pop('nodes', None)
- return [structure_node]
- else:
- leaf_nodes = []
- for key in list(structure.keys()):
- if 'nodes' in key:
- leaf_nodes.extend(get_leaf_nodes(structure[key]))
- return leaf_nodes
- elif isinstance(structure, list):
- leaf_nodes = []
- for item in structure:
- leaf_nodes.extend(get_leaf_nodes(item))
- return leaf_nodes
-
-def is_leaf_node(data, node_id):
- # Helper function to find the node by its node_id
- def find_node(data, node_id):
- if isinstance(data, dict):
- if data.get('node_id') == node_id:
- return data
- for key in data.keys():
- if 'nodes' in key:
- result = find_node(data[key], node_id)
- if result:
- return result
- elif isinstance(data, list):
- for item in data:
- result = find_node(item, node_id)
- if result:
- return result
- return None
-
- # Find the node with the given node_id
- node = find_node(data, node_id)
-
- # Check if the node is a leaf node
- if node and not node.get('nodes'):
- return True
- return False
-
-def get_last_node(structure):
- return structure[-1]
-
-
-def extract_text_from_pdf(pdf_path):
- pdf_reader = PyPDF2.PdfReader(pdf_path)
- ###return text not list
- text=""
- for page_num in range(len(pdf_reader.pages)):
- page = pdf_reader.pages[page_num]
- text+=page.extract_text()
- return text
-
-def get_pdf_title(pdf_path):
- pdf_reader = PyPDF2.PdfReader(pdf_path)
- meta = pdf_reader.metadata
- title = meta.title if meta and meta.title else 'Untitled'
- return title
-
-def get_text_of_pages(pdf_path, start_page, end_page, tag=True):
- pdf_reader = PyPDF2.PdfReader(pdf_path)
- text = ""
- for page_num in range(start_page-1, end_page):
- page = pdf_reader.pages[page_num]
- page_text = page.extract_text()
- if tag:
- text += f"\n{page_text}\n\n"
- else:
- text += page_text
- return text
-
-def get_first_start_page_from_text(text):
- start_page = -1
- start_page_match = re.search(r'', text)
- if start_page_match:
- start_page = int(start_page_match.group(1))
- return start_page
-
-def get_last_start_page_from_text(text):
- start_page = -1
- # Find all matches of start_index tags
- start_page_matches = re.finditer(r'', text)
- # Convert iterator to list and get the last match if any exist
- matches_list = list(start_page_matches)
- if matches_list:
- start_page = int(matches_list[-1].group(1))
- return start_page
-
-
-def sanitize_filename(filename, replacement='-'):
- # In Linux, only '/' and '\0' (null) are invalid in filenames.
- # Null can't be represented in strings, so we only handle '/'.
- return filename.replace('/', replacement)
-
-def get_pdf_name(pdf_path):
- # Extract PDF name
- if isinstance(pdf_path, str):
- pdf_name = os.path.basename(pdf_path)
- elif isinstance(pdf_path, BytesIO):
- pdf_reader = PyPDF2.PdfReader(pdf_path)
- meta = pdf_reader.metadata
- pdf_name = meta.title if meta and meta.title else 'Untitled'
- pdf_name = sanitize_filename(pdf_name)
- return pdf_name
-
-
-class JsonLogger:
- def __init__(self, file_path):
- # Extract PDF name for logger name
- pdf_name = get_pdf_name(file_path)
-
- current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
- self.filename = f"{pdf_name}_{current_time}.json"
- os.makedirs("./logs", exist_ok=True)
- # Initialize empty list to store all messages
- self.log_data = []
-
- def log(self, level, message, **kwargs):
- if isinstance(message, dict):
- self.log_data.append(message)
- else:
- self.log_data.append({'message': message})
- # Add new message to the log data
-
- # Write entire log data to file
- with open(self._filepath(), "w") as f:
- json.dump(self.log_data, f, indent=2)
-
- def info(self, message, **kwargs):
- self.log("INFO", message, **kwargs)
-
- def error(self, message, **kwargs):
- self.log("ERROR", message, **kwargs)
-
- def debug(self, message, **kwargs):
- self.log("DEBUG", message, **kwargs)
-
- def exception(self, message, **kwargs):
- kwargs["exception"] = True
- self.log("ERROR", message, **kwargs)
-
- def _filepath(self):
- return os.path.join("logs", self.filename)
-
-
-
-
-def list_to_tree(data):
- def get_parent_structure(structure):
- """Helper function to get the parent structure code"""
- if not structure:
- return None
- parts = str(structure).split('.')
- return '.'.join(parts[:-1]) if len(parts) > 1 else None
-
- # First pass: Create nodes and track parent-child relationships
- nodes = {}
- root_nodes = []
-
- for item in data:
- structure = item.get('structure')
- node = {
- 'title': item.get('title'),
- 'start_index': item.get('start_index'),
- 'end_index': item.get('end_index'),
- 'nodes': []
- }
-
- nodes[structure] = node
-
- # Find parent
- parent_structure = get_parent_structure(structure)
-
- if parent_structure:
- # Add as child to parent if parent exists
- if parent_structure in nodes:
- nodes[parent_structure]['nodes'].append(node)
- else:
- root_nodes.append(node)
- else:
- # No parent, this is a root node
- root_nodes.append(node)
-
- # Helper function to clean empty children arrays
- def clean_node(node):
- if not node['nodes']:
- del node['nodes']
- else:
- for child in node['nodes']:
- clean_node(child)
- return node
-
- # Clean and return the tree
- return [clean_node(node) for node in root_nodes]
-
-def add_preface_if_needed(data):
- if not isinstance(data, list) or not data:
- return data
-
- if data[0]['physical_index'] is not None and data[0]['physical_index'] > 1:
- preface_node = {
- "structure": "0",
- "title": "Preface",
- "physical_index": 1,
- }
- data.insert(0, preface_node)
- return data
-
-
-
-def get_page_tokens(pdf_path, model="gpt-4o-2024-11-20", pdf_parser="PyPDF2"):
- enc = tiktoken.encoding_for_model(model)
- if pdf_parser == "PyPDF2":
- pdf_reader = PyPDF2.PdfReader(pdf_path)
- page_list = []
- for page_num in range(len(pdf_reader.pages)):
- page = pdf_reader.pages[page_num]
- page_text = page.extract_text()
- token_length = len(enc.encode(page_text))
- page_list.append((page_text, token_length))
- return page_list
- elif pdf_parser == "PyMuPDF":
- if isinstance(pdf_path, BytesIO):
- pdf_stream = pdf_path
- doc = pymupdf.open(stream=pdf_stream, filetype="pdf")
- elif isinstance(pdf_path, str) and os.path.isfile(pdf_path) and pdf_path.lower().endswith(".pdf"):
- doc = pymupdf.open(pdf_path)
- page_list = []
- for page in doc:
- page_text = page.get_text()
- token_length = len(enc.encode(page_text))
- page_list.append((page_text, token_length))
- return page_list
- else:
- raise ValueError(f"Unsupported PDF parser: {pdf_parser}")
-
-
-
-def get_text_of_pdf_pages(pdf_pages, start_page, end_page):
- text = ""
- for page_num in range(start_page-1, end_page):
- text += pdf_pages[page_num][0]
- return text
-
-def get_text_of_pdf_pages_with_labels(pdf_pages, start_page, end_page):
- text = ""
- for page_num in range(start_page-1, end_page):
- text += f"\n{pdf_pages[page_num][0]}\n\n"
- return text
-
-def get_number_of_pages(pdf_path):
- pdf_reader = PyPDF2.PdfReader(pdf_path)
- num = len(pdf_reader.pages)
- return num
-
-
-
-def post_processing(structure, end_physical_index):
- # First convert page_number to start_index in flat list
- for i, item in enumerate(structure):
- item['start_index'] = item.get('physical_index')
- if i < len(structure) - 1:
- if structure[i + 1].get('appear_start') == 'yes':
- item['end_index'] = structure[i + 1]['physical_index']-1
- else:
- item['end_index'] = structure[i + 1]['physical_index']
- else:
- item['end_index'] = end_physical_index
- tree = list_to_tree(structure)
- if len(tree)!=0:
- return tree
- else:
- ### remove appear_start
- for node in structure:
- node.pop('appear_start', None)
- node.pop('physical_index', None)
- return structure
-
-def clean_structure_post(data):
- if isinstance(data, dict):
- data.pop('page_number', None)
- data.pop('start_index', None)
- data.pop('end_index', None)
- if 'nodes' in data:
- clean_structure_post(data['nodes'])
- elif isinstance(data, list):
- for section in data:
- clean_structure_post(section)
- return data
-
-def remove_fields(data, fields=['text']):
- if isinstance(data, dict):
- return {k: remove_fields(v, fields)
- for k, v in data.items() if k not in fields}
- elif isinstance(data, list):
- return [remove_fields(item, fields) for item in data]
- return data
-
-def print_toc(tree, indent=0):
- for node in tree:
- print(' ' * indent + node['title'])
- if node.get('nodes'):
- print_toc(node['nodes'], indent + 1)
-
-def print_json(data, max_len=40, indent=2):
- def simplify_data(obj):
- if isinstance(obj, dict):
- return {k: simplify_data(v) for k, v in obj.items()}
- elif isinstance(obj, list):
- return [simplify_data(item) for item in obj]
- elif isinstance(obj, str) and len(obj) > max_len:
- return obj[:max_len] + '...'
- else:
- return obj
-
- simplified = simplify_data(data)
- print(json.dumps(simplified, indent=indent, ensure_ascii=False))
-
-
-def remove_structure_text(data):
- if isinstance(data, dict):
- data.pop('text', None)
- if 'nodes' in data:
- remove_structure_text(data['nodes'])
- elif isinstance(data, list):
- for item in data:
- remove_structure_text(item)
- return data
-
-
-def check_token_limit(structure, limit=110000):
- list = structure_to_list(structure)
- for node in list:
- num_tokens = count_tokens(node['text'], model='gpt-4o')
- if num_tokens > limit:
- print(f"Node ID: {node['node_id']} has {num_tokens} tokens")
- print("Start Index:", node['start_index'])
- print("End Index:", node['end_index'])
- print("Title:", node['title'])
- print("\n")
-
-
-def convert_physical_index_to_int(data):
- if isinstance(data, list):
- for i in range(len(data)):
- # Check if item is a dictionary and has 'physical_index' key
- if isinstance(data[i], dict) and 'physical_index' in data[i]:
- if isinstance(data[i]['physical_index'], str):
- if data[i]['physical_index'].startswith('').strip())
- elif data[i]['physical_index'].startswith('physical_index_'):
- data[i]['physical_index'] = int(data[i]['physical_index'].split('_')[-1].strip())
- elif isinstance(data, str):
- if data.startswith('').strip())
- elif data.startswith('physical_index_'):
- data = int(data.split('_')[-1].strip())
- # Check data is int
- if isinstance(data, int):
- return data
- else:
- return None
- return data
-
-
-def convert_page_to_int(data):
- for item in data:
- if 'page' in item and isinstance(item['page'], str):
- try:
- item['page'] = int(item['page'])
- except ValueError:
- # Keep original value if conversion fails
- pass
- return data
-
-
-def add_node_text(node, pdf_pages):
- if isinstance(node, dict):
- start_page = node.get('start_index')
- end_page = node.get('end_index')
- node['text'] = get_text_of_pdf_pages(pdf_pages, start_page, end_page)
- if 'nodes' in node:
- add_node_text(node['nodes'], pdf_pages)
- elif isinstance(node, list):
- for index in range(len(node)):
- add_node_text(node[index], pdf_pages)
- return
-
-
-def add_node_text_with_labels(node, pdf_pages):
- if isinstance(node, dict):
- start_page = node.get('start_index')
- end_page = node.get('end_index')
- node['text'] = get_text_of_pdf_pages_with_labels(pdf_pages, start_page, end_page)
- if 'nodes' in node:
- add_node_text_with_labels(node['nodes'], pdf_pages)
- elif isinstance(node, list):
- for index in range(len(node)):
- add_node_text_with_labels(node[index], pdf_pages)
- return
-
-
-async def generate_node_summary(node, model=None):
- prompt = f"""You are given a part of a document, your task is to generate a description of the partial document about what are main points covered in the partial document.
-
- Partial Document Text: {node['text']}
-
- Directly return the description, do not include any other text.
- """
- response = await ChatGPT_API_async(model, prompt)
- return response
-
-
-async def generate_summaries_for_structure(structure, model=None):
- nodes = structure_to_list(structure)
- tasks = [generate_node_summary(node, model=model) for node in nodes]
- summaries = await asyncio.gather(*tasks)
-
- for node, summary in zip(nodes, summaries):
- node['summary'] = summary
- return structure
-
-
-def create_clean_structure_for_description(structure):
- """
- Create a clean structure for document description generation,
- excluding unnecessary fields like 'text'.
- """
- if isinstance(structure, dict):
- clean_node = {}
- # Only include essential fields for description
- for key in ['title', 'node_id', 'summary', 'prefix_summary']:
- if key in structure:
- clean_node[key] = structure[key]
-
- # Recursively process child nodes
- if 'nodes' in structure and structure['nodes']:
- clean_node['nodes'] = create_clean_structure_for_description(structure['nodes'])
-
- return clean_node
- elif isinstance(structure, list):
- return [create_clean_structure_for_description(item) for item in structure]
- else:
- return structure
-
-
-def generate_doc_description(structure, model=None):
- prompt = f"""Your are an expert in generating descriptions for a document.
- You are given a structure of a document. Your task is to generate a one-sentence description for the document, which makes it easy to distinguish the document from other documents.
-
- Document Structure: {structure}
-
- Directly return the description, do not include any other text.
- """
- response = ChatGPT_API(model, prompt)
- return response
-
-
-def reorder_dict(data, key_order):
- if not key_order:
- return data
- return {key: data[key] for key in key_order if key in data}
-
-
-def format_structure(structure, order=None):
- if not order:
- return structure
- if isinstance(structure, dict):
- if 'nodes' in structure:
- structure['nodes'] = format_structure(structure['nodes'], order)
- if not structure.get('nodes'):
- structure.pop('nodes', None)
- structure = reorder_dict(structure, order)
- elif isinstance(structure, list):
- structure = [format_structure(item, order) for item in structure]
- return structure
-
-
-class ConfigLoader:
- def __init__(self, default_path: str = None):
- if default_path is None:
- default_path = Path(__file__).parent / "config.yaml"
- self._default_dict = self._load_yaml(default_path)
-
- @staticmethod
- def _load_yaml(path):
- with open(path, "r", encoding="utf-8") as f:
- return yaml.safe_load(f) or {}
-
- def _validate_keys(self, user_dict):
- unknown_keys = set(user_dict) - set(self._default_dict)
- if unknown_keys:
- raise ValueError(f"Unknown config keys: {unknown_keys}")
-
- def load(self, user_opt=None) -> config:
- """
- Load the configuration, merging user options with default values.
- """
- if user_opt is None:
- user_dict = {}
- elif isinstance(user_opt, config):
- user_dict = vars(user_opt)
- elif isinstance(user_opt, dict):
- user_dict = user_opt
- else:
- raise TypeError("user_opt must be dict, config(SimpleNamespace) or None")
-
- self._validate_keys(user_dict)
- merged = {**self._default_dict, **user_dict}
- return config(**merged)
\ No newline at end of file
diff --git a/pyproject.toml b/pyproject.toml
new file mode 100644
index 000000000..868b6bfca
--- /dev/null
+++ b/pyproject.toml
@@ -0,0 +1,35 @@
+[build-system]
+requires = ["setuptools>=68", "wheel"]
+build-backend = "setuptools.build_meta"
+
+[project]
+name = "pageindex"
+version = "0.1.0"
+description = "Vectorless, reasoning-based RAG indexer"
+readme = "README.md"
+requires-python = ">=3.9"
+license = {text = "MIT"}
+dependencies = [
+ "openai==1.101.0",
+ "pymupdf==1.26.4",
+ "PyPDF2==3.0.1",
+ "python-dotenv==1.1.0",
+ "tiktoken==0.11.0",
+ "pyyaml==6.0.2",
+ "pydantic>=2.0",
+]
+
+[project.optional-dependencies]
+dev = [
+ "pytest>=7.4.0",
+ "pytest-asyncio>=0.21.0",
+]
+
+[project.scripts]
+pageindex = "pageindex.cli:main"
+
+[tool.setuptools]
+package-dir = {"" = "src"}
+
+[tool.setuptools.packages.find]
+where = ["src"]
diff --git a/src/analyze_notebooks.py b/src/analyze_notebooks.py
new file mode 100644
index 000000000..2fee5e75b
--- /dev/null
+++ b/src/analyze_notebooks.py
@@ -0,0 +1,27 @@
+import json
+import sys
+import glob
+
+def analyze_notebook(path):
+ print(f"--- Analyzing {path} ---")
+ try:
+ with open(path, 'r') as f:
+ nb = json.load(f)
+
+ for i, cell in enumerate(nb['cells']):
+ if cell['cell_type'] == 'code':
+ source = ''.join(cell['source'])
+ print(f"Cell {i}:\n{source}\n")
+ print("-" * 20)
+ except Exception as e:
+ print(f"Error reading {path}: {e}")
+
+if __name__ == "__main__":
+ if len(sys.argv) > 1:
+ for path in sys.argv[1:]:
+ analyze_notebook(path)
+ else:
+ # Default to all notebooks in ../notebooks relative to src
+ notebooks = glob.glob("../notebooks/*.ipynb")
+ for nb in notebooks:
+ analyze_notebook(nb)
diff --git a/src/local_client_adapter.py b/src/local_client_adapter.py
new file mode 100644
index 000000000..269138e83
--- /dev/null
+++ b/src/local_client_adapter.py
@@ -0,0 +1,145 @@
+import os
+import json
+import asyncio
+import uuid
+from typing import List, Dict, Any, Optional
+import sys
+
+# Ensure we can import from src
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+
+from pageindex import page_index
+from pageindex.core.llm import ChatGPT_API_async, extract_json
+import pageindex.utils as utils
+
+class PageIndexClient:
+ def __init__(self, api_key: str = None):
+ self.api_key = api_key
+ self.documents = {} # doc_id -> {status, structure, path, ...}
+
+ def submit_document(self, file_path: str) -> Dict[str, str]:
+ doc_id = str(uuid.uuid4())
+ self.documents[doc_id] = {
+ "status": "processing",
+ "file_path": file_path,
+ "structure": None
+ }
+
+ # In a real app this would be async background work,
+ # but for notebook compatibility we can either block or just set it to run on next access.
+ # Since notebooks check status, we can run it synchronously here or lazily.
+ # Let's run synchronously for simplicity as page_index is blocking/async.
+
+ # We need to run async page_index in a sync context if this method is sync.
+ # But page_index_main uses asyncio.run() internally?
+ # Let's check page_index.py.
+ # page_index() calls ConfigLoader then page_index_main(doc, opt).
+ # page_index_main returns asyncio.run(page_index_builder())
+ # So it IS blocking and synchronous from caller perspective.
+
+ try:
+ result = page_index(file_path)
+ self.documents[doc_id]["structure"] = result["structure"]
+ self.documents[doc_id]["status"] = "completed"
+ self.documents[doc_id]["info"] = {
+ "id": doc_id,
+ "name": os.path.basename(file_path),
+ "status": "completed",
+ "pageNum": 0, # We might need to count pages if not in result
+ "description": result.get("doc_description", "")
+ }
+ except Exception as e:
+ self.documents[doc_id]["status"] = "failed"
+ print(f"Error processing document: {e}")
+
+ return {"doc_id": doc_id}
+
+ def get_document(self, doc_id: str) -> Dict[str, Any]:
+ doc = self.documents.get(doc_id)
+ if not doc:
+ return {"status": "not_found"}
+ return doc.get("info", {"status": doc["status"]})
+
+ def is_retrieval_ready(self, doc_id: str) -> bool:
+ doc = self.documents.get(doc_id)
+ return doc and doc["status"] == "completed"
+
+ def get_tree(self, doc_id: str, node_summary: bool = False) -> Dict[str, Any]:
+ doc = self.documents.get(doc_id)
+ if not doc or not doc["structure"]:
+ return {"result": []}
+ return {"result": doc["structure"]}
+
+ def chat_completions(self, messages: List[Dict[str, str]], doc_id: str, stream: bool = False):
+ # This implementation mimics the RAG flow
+ query = messages[-1]["content"]
+ doc = self.documents.get(doc_id)
+ if not doc or not doc["structure"]:
+ yield "Data not found" if stream else "Data not found"
+ return
+
+ tree = doc["structure"]
+
+ # 1. Search Tree (Async run in sync wrapper?)
+ # Since this method is likely called synchronously in notebooks or awaited?
+ # Notebooks usually use `pi_client.chat_completions` in a loop for stream.
+ # If I can't await here, I have to handle async LLM calls.
+ # But `pageindex.core.llm` has `ChatGPT_API` (sync) and `ChatGPT_API_async`.
+ # I'll use the SYNC version `ChatGPT_API` for simplicity in this adapter.
+
+ from pageindex.core.llm import ChatGPT_API
+
+ # Remove text field for search to save tokens
+ tree_without_text = utils.remove_fields(json.loads(json.dumps(tree)), fields=['text'])
+
+ search_prompt = f"""
+You are given a question and a tree structure of a document.
+Each node contains a node id, node title, and a corresponding summary.
+Your task is to find all nodes that are likely to contain the answer to the question.
+
+Question: {query}
+
+Document tree structure:
+{json.dumps(tree_without_text, indent=2)}
+
+Please reply in the following JSON format:
+{{
+ "thinking": "",
+ "node_list": ["node_id_1", "node_id_2"]
+}}
+Directly return the final JSON structure.
+"""
+ tree_search_result = ChatGPT_API(model="gpt-4o", prompt=search_prompt)
+ try:
+ tree_search_json = extract_json(tree_search_result)
+ node_ids = tree_search_json.get("node_list", [])
+ except:
+ node_ids = []
+
+ # 2. Retrieve Context
+ node_map = utils.create_node_mapping(tree)
+ relevant_content = ""
+ for nid in node_ids:
+ if nid in node_map:
+ relevant_content += node_map[nid].get("text", "") + "\n\n"
+
+ # 3. Generate Answer
+ answer_prompt = f"""
+Answer the question based on the context:
+
+Question: {query}
+Context: {relevant_content[:20000]}
+
+Provide a clear, concise answer.
+"""
+ answer = ChatGPT_API(model="gpt-4o", prompt=answer_prompt)
+
+ # Simulate stream by yielding chunks (or just one chunk)
+ if stream:
+ yield answer
+ else:
+ return answer
+
+# Helper for notebooks to import
+def get_client(api_key=None):
+ return PageIndexClient(api_key=api_key)
diff --git a/pageindex/__init__.py b/src/pageindex/__init__.py
similarity index 100%
rename from pageindex/__init__.py
rename to src/pageindex/__init__.py
diff --git a/run_pageindex.py b/src/pageindex/cli.py
similarity index 58%
rename from run_pageindex.py
rename to src/pageindex/cli.py
index 107024505..dd397c95a 100644
--- a/run_pageindex.py
+++ b/src/pageindex/cli.py
@@ -1,40 +1,58 @@
import argparse
-import os
import json
-from pageindex import *
-from pageindex.page_index_md import md_to_tree
+import os
-if __name__ == "__main__":
- # Set up argument parser
- parser = argparse.ArgumentParser(description='Process PDF or Markdown document and generate structure')
+from .page_index import page_index_main
+from .page_index_md import md_to_tree
+from .config import ConfigLoader
+
+
+def _build_config_overrides(args):
+ candidates = {
+ 'model': args.model,
+ 'toc_check_page_num': args.toc_check_pages,
+ 'max_page_num_each_node': args.max_pages_per_node,
+ 'max_token_num_each_node': args.max_tokens_per_node,
+ 'if_add_node_id': args.if_add_node_id,
+ 'if_add_node_summary': args.if_add_node_summary,
+ 'if_add_doc_description': args.if_add_doc_description,
+ 'if_add_node_text': args.if_add_node_text,
+ }
+ return {key: value for key, value in candidates.items() if value is not None}
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description='Process PDF or Markdown document and generate structure'
+ )
parser.add_argument('--pdf_path', type=str, help='Path to the PDF file')
parser.add_argument('--md_path', type=str, help='Path to the Markdown file')
- parser.add_argument('--model', type=str, default='gpt-4o-2024-11-20', help='Model to use')
+ parser.add_argument('--model', type=str, default=None, help='Model to use (defaults to config.yaml)')
- parser.add_argument('--toc-check-pages', type=int, default=20,
- help='Number of pages to check for table of contents (PDF only)')
- parser.add_argument('--max-pages-per-node', type=int, default=10,
- help='Maximum number of pages per node (PDF only)')
- parser.add_argument('--max-tokens-per-node', type=int, default=20000,
- help='Maximum number of tokens per node (PDF only)')
+ parser.add_argument('--toc-check-pages', type=int, default=None,
+ help='Number of pages to check for table of contents (PDF only)')
+ parser.add_argument('--max-pages-per-node', type=int, default=None,
+ help='Maximum number of pages per node (PDF only)')
+ parser.add_argument('--max-tokens-per-node', type=int, default=None,
+ help='Maximum number of tokens per node (PDF only)')
+
+ parser.add_argument('--if-add-node-id', type=str, default=None,
+ help='Whether to add node id to the node')
+ parser.add_argument('--if-add-node-summary', type=str, default=None,
+ help='Whether to add summary to the node')
+ parser.add_argument('--if-add-doc-description', type=str, default=None,
+ help='Whether to add doc description to the doc')
+ parser.add_argument('--if-add-node-text', type=str, default=None,
+ help='Whether to add text to the node')
- parser.add_argument('--if-add-node-id', type=str, default='yes',
- help='Whether to add node id to the node')
- parser.add_argument('--if-add-node-summary', type=str, default='yes',
- help='Whether to add summary to the node')
- parser.add_argument('--if-add-doc-description', type=str, default='no',
- help='Whether to add doc description to the doc')
- parser.add_argument('--if-add-node-text', type=str, default='no',
- help='Whether to add text to the node')
-
# Markdown specific arguments
parser.add_argument('--if-thinning', type=str, default='no',
- help='Whether to apply tree thinning for markdown (markdown only)')
+ help='Whether to apply tree thinning for markdown (markdown only)')
parser.add_argument('--thinning-threshold', type=int, default=5000,
- help='Minimum token threshold for thinning (markdown only)')
+ help='Minimum token threshold for thinning (markdown only)')
parser.add_argument('--summary-token-threshold', type=int, default=200,
- help='Token threshold for generating summaries (markdown only)')
+ help='Token threshold for generating summaries (markdown only)')
args = parser.parse_args()
# Validate that exactly one file type is specified
@@ -43,6 +61,9 @@
if args.pdf_path and args.md_path:
raise ValueError("Only one of --pdf_path or --md_path can be specified")
+ config_loader = ConfigLoader()
+ opt = config_loader.load(_build_config_overrides(args))
+
if args.pdf_path:
# Validate PDF file
if not args.pdf_path.lower().endswith('.pdf'):
@@ -50,20 +71,6 @@
if not os.path.isfile(args.pdf_path):
raise ValueError(f"PDF file not found: {args.pdf_path}")
- # Process PDF file
- # Configure options
- opt = config(
- model=args.model,
- toc_check_page_num=args.toc_check_pages,
- max_page_num_each_node=args.max_pages_per_node,
- max_token_num_each_node=args.max_tokens_per_node,
- if_add_node_id=args.if_add_node_id,
- if_add_node_summary=args.if_add_node_summary,
- if_add_doc_description=args.if_add_doc_description,
- if_add_node_text=args.if_add_node_text
- )
-
- # Process the PDF
toc_with_page_number = page_index_main(args.pdf_path, opt)
print('Parsing done, saving to file...')
@@ -91,22 +98,6 @@
# Process the markdown
import asyncio
- # Use ConfigLoader to get consistent defaults (matching PDF behavior)
- from pageindex.utils import ConfigLoader
- config_loader = ConfigLoader()
-
- # Create options dict with user args
- user_opt = {
- 'model': args.model,
- 'if_add_node_summary': args.if_add_node_summary,
- 'if_add_doc_description': args.if_add_doc_description,
- 'if_add_node_text': args.if_add_node_text,
- 'if_add_node_id': args.if_add_node_id
- }
-
- # Load config with defaults from config.yaml
- opt = config_loader.load(user_opt)
-
toc_with_page_number = asyncio.run(md_to_tree(
md_path=args.md_path,
if_thinning=args.if_thinning.lower() == 'yes',
@@ -130,4 +121,8 @@
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(toc_with_page_number, f, indent=2, ensure_ascii=False)
- print(f'Tree structure saved to: {output_file}')
\ No newline at end of file
+ print(f'Tree structure saved to: {output_file}')
+
+
+if __name__ == "__main__":
+ main()
diff --git a/src/pageindex/config.py b/src/pageindex/config.py
new file mode 100644
index 000000000..c1dc82b9f
--- /dev/null
+++ b/src/pageindex/config.py
@@ -0,0 +1,90 @@
+import os
+import yaml
+from pathlib import Path
+from typing import Any, Dict, Optional, Union
+from pydantic import BaseModel, Field, ValidationError
+
+class PageIndexConfig(BaseModel):
+ """
+ Configuration schema for PageIndex.
+ """
+ model: str = Field(default="gpt-4o", description="LLM model to use")
+
+ # PDF Processing
+ toc_check_page_num: int = Field(default=3, description="Number of pages to check for TOC")
+ max_page_num_each_node: int = Field(default=5, description="Maximum pages per leaf node")
+ max_token_num_each_node: int = Field(default=4000, description="Max tokens per node") # Approx
+
+ # Enrichment
+ if_add_node_id: bool = Field(default=True, description="Add unique ID to nodes")
+ if_add_node_summary: bool = Field(default=True, description="Generate summary for nodes")
+ if_add_doc_description: bool = Field(default=True, description="Generate doc-level description")
+ if_add_node_text: bool = Field(default=True, description="Keep raw text in nodes")
+
+ # Tree Optimization
+ if_thinning: bool = Field(default=True, description="Merge small adjacent nodes")
+ thinning_threshold: int = Field(default=500, description="Token threshold for merging")
+ summary_token_threshold: int = Field(default=200, description="Min tokens required to trigger summary generation")
+
+ # Additional
+ api_key: Optional[str] = Field(default=None, description="OpenAI API Key (optional, prefers env var)")
+
+ class Config:
+ arbitrary_types_allowed = True
+
+
+class ConfigLoader:
+ def __init__(self, default_path: Optional[Union[str, Path]] = None):
+ if default_path is None:
+ env_path = os.getenv("PAGEINDEX_CONFIG")
+ if env_path:
+ default_path = Path(env_path)
+ else:
+ cwd_path = Path.cwd() / "config.yaml"
+ repo_path = Path(__file__).resolve().parents[2] / "config.yaml"
+ default_path = cwd_path if cwd_path.exists() else repo_path
+
+ self.default_path = default_path
+ self._default_dict = self._load_yaml(default_path) if default_path else {}
+
+ @staticmethod
+ def _load_yaml(path: Optional[Path]) -> Dict[str, Any]:
+ if not path or not path.exists():
+ return {}
+ try:
+ with open(path, "r", encoding="utf-8") as f:
+ return yaml.safe_load(f) or {}
+ except Exception as e:
+ print(f"Warning: Failed to load config from {path}: {e}")
+ return {}
+
+ def load(self, user_opt: Optional[Union[Dict[str, Any], Any]] = None) -> PageIndexConfig:
+ """
+ Load configuration, merging defaults with user overrides and validating via Pydantic.
+
+ Args:
+ user_opt: Dictionary or object with overrides.
+
+ Returns:
+ PageIndexConfig: Validated configuration object.
+ """
+ user_dict: Dict[str, Any] = {}
+ if user_opt is None:
+ pass
+ elif hasattr(user_opt, '__dict__'):
+ # Handle SimpleNamespace or other objects
+ user_dict = {k: v for k, v in vars(user_opt).items() if v is not None}
+ elif isinstance(user_opt, dict):
+ user_dict = {k: v for k, v in user_opt.items() if v is not None}
+ else:
+ raise TypeError(f"user_opt must be dict or object, got {type(user_opt)}")
+
+ # Merge defaults and user overrides
+ # Pydantic accepts kwargs, efficiently merging
+ merged_data = {**self._default_dict, **user_dict}
+
+ try:
+ return PageIndexConfig(**merged_data)
+ except ValidationError as e:
+ # Re-raise nicely or log
+ raise ValueError(f"Configuration validation failed: {e}")
diff --git a/src/pageindex/core/__init__.py b/src/pageindex/core/__init__.py
new file mode 100644
index 000000000..e69de29bb
diff --git a/src/pageindex/core/llm.py b/src/pageindex/core/llm.py
new file mode 100644
index 000000000..264788c76
--- /dev/null
+++ b/src/pageindex/core/llm.py
@@ -0,0 +1,245 @@
+import tiktoken
+import openai
+import logging
+import os
+import time
+import json
+import asyncio
+from typing import Optional, List, Dict, Any, Union, Tuple
+from dotenv import load_dotenv
+
+load_dotenv()
+
+OPENAI_API_KEY = os.getenv("OPENAI_API_KEY") or os.getenv("CHATGPT_API_KEY")
+
+def count_tokens(text: Optional[str], model: str = "gpt-4o") -> int:
+ """
+ Count the number of tokens in a text string using the specified model's encoding.
+
+ Args:
+ text (Optional[str]): The text to encode. If None, returns 0.
+ model (str): The model name to use for encoding. Defaults to "gpt-4o".
+
+ Returns:
+ int: The number of tokens.
+ """
+ if not text:
+ return 0
+ try:
+ enc = tiktoken.encoding_for_model(model)
+ except KeyError:
+ # Fallback for newer or unknown models
+ enc = tiktoken.get_encoding("cl100k_base")
+ tokens = enc.encode(text)
+ return len(tokens)
+
+def ChatGPT_API_with_finish_reason(
+ model: str,
+ prompt: str,
+ api_key: Optional[str] = OPENAI_API_KEY,
+ chat_history: Optional[List[Dict[str, str]]] = None
+) -> Tuple[str, str]:
+ """
+ Call OpenAI Chat Completion API and return content along with finish reason.
+
+ Args:
+ model (str): The model name (e.g., "gpt-4o").
+ prompt (str): The user prompt.
+ api_key (Optional[str]): OpenAI API key. Defaults to env var.
+ chat_history (Optional[List[Dict[str, str]]]): Previous messages for context.
+
+ Returns:
+ Tuple[str, str]: A tuple containing (content, finish_reason).
+ Returns ("Error", "error") if max retries reached.
+ """
+ max_retries = 10
+ if not api_key:
+ logging.error("No API key provided.")
+ return "Error", "missing_api_key"
+
+ client = openai.OpenAI(api_key=api_key)
+ for i in range(max_retries):
+ try:
+ if chat_history:
+ messages = chat_history.copy() # Avoid modifying original list if passed by ref (shallow copy enough for append)
+ messages.append({"role": "user", "content": prompt})
+ else:
+ messages = [{"role": "user", "content": prompt}]
+
+ response = client.chat.completions.create(
+ model=model,
+ messages=messages,
+ temperature=0,
+ )
+
+ content = response.choices[0].message.content or ""
+ finish_reason = response.choices[0].finish_reason
+
+ if finish_reason == "length":
+ return content, "max_output_reached"
+ else:
+ return content, "finished"
+
+ except Exception as e:
+ print('************* Retrying *************')
+ logging.error(f"Error: {e}")
+ if i < max_retries - 1:
+ time.sleep(1)
+ else:
+ logging.error('Max retries reached for prompt: ' + prompt[:50] + '...')
+ return "Error", "error"
+ return "Error", "max_retries"
+
+def ChatGPT_API(
+ model: str,
+ prompt: str,
+ api_key: Optional[str] = OPENAI_API_KEY,
+ chat_history: Optional[List[Dict[str, str]]] = None
+) -> str:
+ """
+ Call OpenAI Chat Completion API and return the content string.
+
+ Args:
+ model (str): The model name.
+ prompt (str): The user prompt.
+ api_key (Optional[str]): OpenAI API key.
+ chat_history (Optional[List[Dict[str, str]]]): Previous messages.
+
+ Returns:
+ str: The response content, or "Error" if failed.
+ """
+ max_retries = 10
+ if not api_key:
+ logging.error("No API key provided.")
+ return "Error"
+
+ client = openai.OpenAI(api_key=api_key)
+ for i in range(max_retries):
+ try:
+ if chat_history:
+ messages = chat_history.copy()
+ messages.append({"role": "user", "content": prompt})
+ else:
+ messages = [{"role": "user", "content": prompt}]
+
+ response = client.chat.completions.create(
+ model=model,
+ messages=messages,
+ temperature=0,
+ )
+
+ return response.choices[0].message.content or ""
+ except Exception as e:
+ print('************* Retrying *************')
+ logging.error(f"Error: {e}")
+ if i < max_retries - 1:
+ time.sleep(1)
+ else:
+ logging.error('Max retries reached for prompt: ' + prompt[:50] + '...')
+ return "Error"
+ return "Error"
+
+async def ChatGPT_API_async(
+ model: str,
+ prompt: str,
+ api_key: Optional[str] = OPENAI_API_KEY
+) -> str:
+ """
+ Asynchronously call OpenAI Chat Completion API.
+
+ Args:
+ model (str): The model name.
+ prompt (str): The user prompt.
+ api_key (Optional[str]): OpenAI API key.
+
+ Returns:
+ str: The response content, or "Error" if failed.
+ """
+ max_retries = 10
+ if not api_key:
+ logging.error("No API key provided.")
+ return "Error"
+
+ messages = [{"role": "user", "content": prompt}]
+ for i in range(max_retries):
+ try:
+ async with openai.AsyncOpenAI(api_key=api_key) as client:
+ response = await client.chat.completions.create(
+ model=model,
+ messages=messages,
+ temperature=0,
+ )
+ return response.choices[0].message.content or ""
+ except Exception as e:
+ print('************* Retrying *************')
+ logging.error(f"Error: {e}")
+ if i < max_retries - 1:
+ await asyncio.sleep(1)
+ else:
+ logging.error('Max retries reached for prompt: ' + prompt[:50] + '...')
+ return "Error"
+ return "Error"
+
+def get_json_content(response: str) -> str:
+ """
+ Extract content inside markdown JSON code blocks.
+
+ Args:
+ response (str): The full raw response string.
+
+ Returns:
+ str: The extracted JSON string stripped of markers.
+ """
+ start_idx = response.find("```json")
+ if start_idx != -1:
+ start_idx += 7
+ response = response[start_idx:]
+
+ end_idx = response.rfind("```")
+ if end_idx != -1:
+ response = response[:end_idx]
+
+ json_content = response.strip()
+ return json_content
+
+def extract_json(content: str) -> Union[Dict[str, Any], List[Any]]:
+ """
+ Robustly extract and parse JSON from a string, handling common LLM formatting issues.
+
+ Args:
+ content (str): The text containing JSON.
+
+ Returns:
+ Union[Dict, List]: The parsed JSON object or empty dict/list on failure.
+ """
+ try:
+ # First, try to extract JSON enclosed within ```json and ```
+ start_idx = content.find("```json")
+ if start_idx != -1:
+ start_idx += 7 # Adjust index to start after the delimiter
+ end_idx = content.rfind("```")
+ json_content = content[start_idx:end_idx].strip()
+ else:
+ # If no delimiters, assume entire content could be JSON
+ json_content = content.strip()
+
+ # Clean up common issues that might cause parsing errors
+ json_content = json_content.replace('None', 'null') # Replace Python None with JSON null
+ json_content = json_content.replace('\n', ' ').replace('\r', ' ') # Remove newlines
+ json_content = ' '.join(json_content.split()) # Normalize whitespace
+
+ # Attempt to parse and return the JSON object
+ return json.loads(json_content)
+ except json.JSONDecodeError as e:
+ logging.error(f"Failed to extract JSON: {e}")
+ # Try to clean up the content further if initial parsing fails
+ try:
+ # Remove any trailing commas before closing brackets/braces
+ json_content = json_content.replace(',]', ']').replace(',}', '}')
+ return json.loads(json_content)
+ except:
+ logging.error("Failed to parse JSON even after cleanup")
+ return {}
+ except Exception as e:
+ logging.error(f"Unexpected error while extracting JSON: {e}")
+ return {}
diff --git a/src/pageindex/core/logging.py b/src/pageindex/core/logging.py
new file mode 100644
index 000000000..e8a27e95d
--- /dev/null
+++ b/src/pageindex/core/logging.py
@@ -0,0 +1,65 @@
+import os
+import json
+from datetime import datetime
+from typing import Any, Dict, Optional, Union
+from .pdf import get_pdf_name
+
+class JsonLogger:
+ """
+ A simple JSON-based logger that writes distinct log files for each run session.
+ """
+ def __init__(self, file_path: Union[str, Any]):
+ """
+ Initialize the logger.
+
+ Args:
+ file_path (Union[str, Any]): The source file path (usually PDF) to derive the log filename from.
+ """
+ # Extract PDF name for logger name
+ pdf_name = get_pdf_name(file_path)
+
+ current_time = datetime.now().strftime("%Y%m%d_%H%M%S")
+ self.filename = f"{pdf_name}_{current_time}.json"
+ os.makedirs("./logs", exist_ok=True)
+ # Initialize empty list to store all messages
+ self.log_data: List[Dict[str, Any]] = []
+
+ def log(self, level: str, message: Union[str, Dict[str, Any]], **kwargs: Any) -> None:
+ """
+ Log a message.
+
+ Args:
+ level (str): Log level (INFO, ERROR, etc.)
+ message (Union[str, Dict]): The message content.
+ """
+ entry: Dict[str, Any] = {}
+ if isinstance(message, dict):
+ entry = message
+ else:
+ entry = {'message': message}
+
+ entry['level'] = level
+ entry['timestamp'] = datetime.now().isoformat()
+ entry.update(kwargs)
+
+ self.log_data.append(entry)
+
+ # Write entire log data to file (inefficient for large logs, but simple for now)
+ with open(self._filepath(), "w", encoding='utf-8') as f:
+ json.dump(self.log_data, f, indent=2, ensure_ascii=False)
+
+ def info(self, message: Union[str, Dict[str, Any]], **kwargs: Any) -> None:
+ self.log("INFO", message, **kwargs)
+
+ def error(self, message: Union[str, Dict[str, Any]], **kwargs: Any) -> None:
+ self.log("ERROR", message, **kwargs)
+
+ def debug(self, message: Union[str, Dict[str, Any]], **kwargs: Any) -> None:
+ self.log("DEBUG", message, **kwargs)
+
+ def exception(self, message: Union[str, Dict[str, Any]], **kwargs: Any) -> None:
+ kwargs["exception"] = True
+ self.log("ERROR", message, **kwargs)
+
+ def _filepath(self) -> str:
+ return os.path.join("logs", self.filename)
diff --git a/src/pageindex/core/pdf.py b/src/pageindex/core/pdf.py
new file mode 100644
index 000000000..855c08566
--- /dev/null
+++ b/src/pageindex/core/pdf.py
@@ -0,0 +1,207 @@
+import PyPDF2
+import pymupdf
+import re
+import os
+import tiktoken
+from io import BytesIO
+from typing import List, Tuple, Union, Optional
+from .llm import count_tokens
+
+def extract_text_from_pdf(pdf_path: str) -> str:
+ """
+ Extract all text from a PDF file using PyPDF2.
+
+ Args:
+ pdf_path (str): Path to the PDF file.
+
+ Returns:
+ str: Concatenated text from all pages.
+ """
+ pdf_reader = PyPDF2.PdfReader(pdf_path)
+ text = ""
+ for page_num in range(len(pdf_reader.pages)):
+ page = pdf_reader.pages[page_num]
+ text += page.extract_text()
+ return text
+
+def get_pdf_title(pdf_path: Union[str, BytesIO]) -> str:
+ """
+ Extract the title from PDF metadata.
+
+ Args:
+ pdf_path (Union[str, BytesIO]): Path to PDF or BytesIO object.
+
+ Returns:
+ str: Title of the PDF or 'Untitled'.
+ """
+ pdf_reader = PyPDF2.PdfReader(pdf_path)
+ meta = pdf_reader.metadata
+ title = meta.title if meta and meta.title else 'Untitled'
+ return title
+
+def get_text_of_pages(pdf_path: str, start_page: int, end_page: int, tag: bool = True) -> str:
+ """
+ Get text from a specific range of pages in a PDF.
+
+ Args:
+ pdf_path (str): Path to the PDF file.
+ start_page (int): Start page number (1-based).
+ end_page (int): End page number (1-based).
+ tag (bool): If True, wraps page text in ... tags.
+
+ Returns:
+ str: Extracted text.
+ """
+ pdf_reader = PyPDF2.PdfReader(pdf_path)
+ text = ""
+ for page_num in range(start_page-1, end_page):
+ if page_num < len(pdf_reader.pages):
+ page = pdf_reader.pages[page_num]
+ page_text = page.extract_text()
+ if tag:
+ text += f"\n{page_text}\n\n"
+ else:
+ text += page_text
+ return text
+
+def get_first_start_page_from_text(text: str) -> int:
+ """
+ Extract the first page index tag found in text.
+
+ Args:
+ text (str): Text containing tags.
+
+ Returns:
+ int: Page number or -1 if not found.
+ """
+ start_page = -1
+ start_page_match = re.search(r'', text)
+ if start_page_match:
+ start_page = int(start_page_match.group(1))
+ return start_page
+
+def get_last_start_page_from_text(text: str) -> int:
+ """
+ Extract the last page index tag found in text.
+
+ Args:
+ text (str): Text containing tags.
+
+ Returns:
+ int: Page number or -1 if not found.
+ """
+ start_page = -1
+ start_page_matches = re.finditer(r'', text)
+ matches_list = list(start_page_matches)
+ if matches_list:
+ start_page = int(matches_list[-1].group(1))
+ return start_page
+
+
+def sanitize_filename(filename: str, replacement: str = '-') -> str:
+ """Replace illegal characters in filename."""
+ return filename.replace('/', replacement)
+
+def get_pdf_name(pdf_path: Union[str, BytesIO]) -> str:
+ """
+ Get a sanitized name for the PDF file.
+
+ Args:
+ pdf_path (Union[str, BytesIO]): Path or file object.
+
+ Returns:
+ str: Filename or logical title.
+ """
+ pdf_name = "Untitled.pdf"
+ if isinstance(pdf_path, str):
+ pdf_name = os.path.basename(pdf_path)
+ elif isinstance(pdf_path, BytesIO):
+ pdf_reader = PyPDF2.PdfReader(pdf_path)
+ meta = pdf_reader.metadata
+ if meta and meta.title:
+ pdf_name = meta.title
+ pdf_name = sanitize_filename(pdf_name)
+ return pdf_name
+
+
+def get_page_tokens(
+ pdf_path: Union[str, BytesIO],
+ model: str = "gpt-4o-2024-11-20",
+ pdf_parser: str = "PyPDF2"
+) -> List[Tuple[str, int]]:
+ """
+ Extract text and token counts for each page.
+
+ Args:
+ pdf_path (Union[str, BytesIO]): Path to PDF.
+ model (str): Model name for token counting.
+ pdf_parser (str): "PyPDF2" or "PyMuPDF".
+
+ Returns:
+ List[Tuple[str, int]]: List of (page_text, token_count).
+ """
+ enc = tiktoken.encoding_for_model(model)
+ if pdf_parser == "PyPDF2":
+ pdf_reader = PyPDF2.PdfReader(pdf_path)
+ page_list = []
+ for page_num in range(len(pdf_reader.pages)):
+ page = pdf_reader.pages[page_num]
+ page_text = page.extract_text()
+ token_length = len(enc.encode(page_text))
+ page_list.append((page_text, token_length))
+ return page_list
+ elif pdf_parser == "PyMuPDF":
+ if isinstance(pdf_path, BytesIO):
+ pdf_stream = pdf_path
+ doc = pymupdf.open(stream=pdf_stream, filetype="pdf")
+ elif isinstance(pdf_path, str) and os.path.isfile(pdf_path) and pdf_path.lower().endswith(".pdf"):
+ doc = pymupdf.open(pdf_path)
+ else:
+ raise ValueError(f"Invalid pdf path for PyMuPDF: {pdf_path}")
+
+ page_list = []
+ for page in doc:
+ page_text = page.get_text()
+ token_length = len(enc.encode(page_text))
+ page_list.append((page_text, token_length))
+ return page_list
+ else:
+ raise ValueError(f"Unsupported PDF parser: {pdf_parser}")
+
+
+
+def get_text_of_pdf_pages(pdf_pages: List[Tuple[str, int]], start_page: int, end_page: int) -> str:
+ """
+ Combine text from a list of page tuples [1-based range].
+
+ Args:
+ pdf_pages (List[Tuple[str, int]]): Output from get_page_tokens.
+ start_page (int): Start page (1-based).
+ end_page (int): End page (1-based, inclusive).
+
+ Returns:
+ str: Combined text.
+ """
+ text = ""
+ # Safe indexing
+ total_pages = len(pdf_pages)
+ for page_num in range(start_page-1, end_page):
+ if 0 <= page_num < total_pages:
+ text += pdf_pages[page_num][0]
+ return text
+
+def get_text_of_pdf_pages_with_labels(pdf_pages: List[Tuple[str, int]], start_page: int, end_page: int) -> str:
+ """
+ Combine text from pages with tags.
+ """
+ text = ""
+ total_pages = len(pdf_pages)
+ for page_num in range(start_page-1, end_page):
+ if 0 <= page_num < total_pages:
+ text += f"\n{pdf_pages[page_num][0]}\n\n"
+ return text
+
+def get_number_of_pages(pdf_path: Union[str, BytesIO]) -> int:
+ """Get total page count of a PDF."""
+ pdf_reader = PyPDF2.PdfReader(pdf_path)
+ return len(pdf_reader.pages)
diff --git a/src/pageindex/core/tree.py b/src/pageindex/core/tree.py
new file mode 100644
index 000000000..762319900
--- /dev/null
+++ b/src/pageindex/core/tree.py
@@ -0,0 +1,545 @@
+import copy
+import json
+import asyncio
+from typing import List, Dict, Any, Optional, Union
+from .llm import count_tokens, ChatGPT_API, ChatGPT_API_async
+
+# Type aliases for tree structures
+Node = Dict[str, Any]
+Tree = List[Node]
+Structure = Union[Node, List[Any]] # Recursive definition limitation in MyPy, using Any for nested
+
+def write_node_id(data: Structure, node_id: int = 0) -> int:
+ """
+ Recursively assign sequential node_ids to a tree structure.
+
+ Args:
+ data (Structure): The tree or node to process.
+ node_id (int): The starting ID.
+
+ Returns:
+ int: The next available node_id.
+ """
+ if isinstance(data, dict):
+ data['node_id'] = str(node_id).zfill(4)
+ node_id += 1
+ for key in list(data.keys()):
+ if 'nodes' in key:
+ node_id = write_node_id(data[key], node_id)
+ elif isinstance(data, list):
+ for index in range(len(data)):
+ node_id = write_node_id(data[index], node_id)
+ return node_id
+
+def get_nodes(structure: Structure) -> List[Node]:
+ """
+ Flatten the tree into a list of nodes, excluding their children 'nodes' list from the copy.
+
+ Args:
+ structure (Structure): The tree structure.
+
+ Returns:
+ List[Node]: A flat list of node dictionaries (without 'nodes' key).
+ """
+ if isinstance(structure, dict):
+ structure_node = copy.deepcopy(structure)
+ structure_node.pop('nodes', None)
+ nodes = [structure_node]
+ for key in list(structure.keys()):
+ if 'nodes' in key:
+ nodes.extend(get_nodes(structure[key]))
+ return nodes
+ elif isinstance(structure, list):
+ nodes = []
+ for item in structure:
+ nodes.extend(get_nodes(item))
+ return nodes
+ return []
+
+def structure_to_list(structure: Structure) -> List[Node]:
+ """
+ Flatten the tree into a list of references to all nodes (including containers).
+
+ Args:
+ structure (Structure): The tree structure.
+
+ Returns:
+ List[Node]: Flat list of all nodes.
+ """
+ if isinstance(structure, dict):
+ nodes = []
+ nodes.append(structure)
+ if 'nodes' in structure:
+ nodes.extend(structure_to_list(structure['nodes']))
+ return nodes
+ elif isinstance(structure, list):
+ nodes = []
+ for item in structure:
+ nodes.extend(structure_to_list(item))
+ return nodes
+ return []
+
+
+def get_leaf_nodes(structure: Structure) -> List[Node]:
+ """
+ Get all leaf nodes (nodes with no children).
+
+ Args:
+ structure (Structure): The tree structure.
+
+ Returns:
+ List[Node]: List of leaf node copies (without 'nodes' key).
+ """
+ if isinstance(structure, dict):
+ if not structure.get('nodes'):
+ structure_node = copy.deepcopy(structure)
+ structure_node.pop('nodes', None)
+ return [structure_node]
+ else:
+ leaf_nodes = []
+ for key in list(structure.keys()):
+ if 'nodes' in key:
+ leaf_nodes.extend(get_leaf_nodes(structure[key]))
+ return leaf_nodes
+ elif isinstance(structure, list):
+ leaf_nodes = []
+ for item in structure:
+ leaf_nodes.extend(get_leaf_nodes(item))
+ return leaf_nodes
+ return []
+
+def is_leaf_node(data: Structure, node_id: str) -> bool:
+ """
+ Check if a node with specific ID is a leaf node.
+
+ Args:
+ data (Structure): The tree structure.
+ node_id (str): The ID to check.
+
+ Returns:
+ bool: True if node exists and has no children.
+ """
+ # Helper function to find the node by its node_id
+ def find_node(data: Structure, node_id: str) -> Optional[Node]:
+ if isinstance(data, dict):
+ if data.get('node_id') == node_id:
+ return data
+ for key in data.keys():
+ if 'nodes' in key:
+ result = find_node(data[key], node_id)
+ if result:
+ return result
+ elif isinstance(data, list):
+ for item in data:
+ result = find_node(item, node_id)
+ if result:
+ return result
+ return None
+
+ # Find the node with the given node_id
+ node = find_node(data, node_id)
+
+ # Check if the node is a leaf node
+ if node and not node.get('nodes'):
+ return True
+ return False
+
+def get_last_node(structure: List[Any]) -> Any:
+ """Get the last element of a list structure."""
+ return structure[-1]
+
+def list_to_tree(data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
+ """
+ Convert a flat list of nodes with dot-notation 'structure' keys (e.g., '1.1')
+ into a nested tree.
+
+ Args:
+ data (List[Dict[str, Any]]): List of node dictionaries.
+
+ Returns:
+ List[Dict[str, Any]]: The nested tree structure.
+ """
+ def get_parent_structure(structure: Optional[str]) -> Optional[str]:
+ """Helper function to get the parent structure code"""
+ if not structure:
+ return None
+ parts = str(structure).split('.')
+ return '.'.join(parts[:-1]) if len(parts) > 1 else None
+
+ # First pass: Create nodes and track parent-child relationships
+ nodes: Dict[str, Dict[str, Any]] = {}
+ root_nodes: List[Dict[str, Any]] = []
+
+ for item in data:
+ structure = str(item.get('structure', ''))
+ node = {
+ 'title': item.get('title'),
+ 'start_index': item.get('start_index'),
+ 'end_index': item.get('end_index'),
+ 'nodes': []
+ }
+
+ nodes[structure] = node
+
+ # Find parent
+ parent_structure = get_parent_structure(structure)
+
+ if parent_structure:
+ # Add as child to parent if parent exists
+ if parent_structure in nodes:
+ nodes[parent_structure]['nodes'].append(node)
+ else:
+ root_nodes.append(node)
+ else:
+ # No parent, this is a root node
+ root_nodes.append(node)
+
+ # Helper function to clean empty children arrays
+ def clean_node(node: Dict[str, Any]) -> Dict[str, Any]:
+ if not node['nodes']:
+ del node['nodes']
+ else:
+ for child in node['nodes']:
+ clean_node(child)
+ return node
+
+ # Clean and return the tree
+ return [clean_node(node) for node in root_nodes]
+
+def add_preface_if_needed(data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
+ """
+ Inject a Preface node if the first node starts after page 1.
+ """
+ if not isinstance(data, list) or not data:
+ return data
+
+ if data[0].get('physical_index') is not None and data[0]['physical_index'] > 1:
+ preface_node = {
+ "structure": "0",
+ "title": "Preface",
+ "physical_index": 1,
+ }
+ data.insert(0, preface_node)
+ return data
+
+
+def post_processing(structure: List[Dict[str, Any]], end_physical_index: int) -> Union[List[Dict[str, Any]], List[Any]]:
+ """
+ Calculate start/end indices based on 'physical_index' and convert to tree if possible.
+
+ Args:
+ structure: List of flat nodes.
+ end_physical_index: Total pages or end index.
+
+ Returns:
+ Tree or List.
+ """
+ # First convert page_number to start_index in flat list
+ for i, item in enumerate(structure):
+ item['start_index'] = item.get('physical_index')
+ if i < len(structure) - 1:
+ if structure[i + 1].get('appear_start') == 'yes':
+ item['end_index'] = structure[i + 1]['physical_index']-1
+ else:
+ item['end_index'] = structure[i + 1]['physical_index']
+ else:
+ item['end_index'] = end_physical_index
+ tree = list_to_tree(structure)
+ if len(tree)!=0:
+ return tree
+ else:
+ ### remove appear_start
+ for node in structure:
+ node.pop('appear_start', None)
+ node.pop('physical_index', None)
+ return structure
+
+def clean_structure_post(data: Structure) -> Structure:
+ """Recursively clean internal processing fields from structure."""
+ if isinstance(data, dict):
+ data.pop('page_number', None)
+ data.pop('start_index', None)
+ data.pop('end_index', None)
+ if 'nodes' in data:
+ clean_structure_post(data['nodes'])
+ elif isinstance(data, list):
+ for section in data:
+ clean_structure_post(section)
+ return data
+
+def remove_fields(data: Structure, fields: List[str] = ['text']) -> Structure:
+ """Recursively remove specified fields from the structure."""
+ if isinstance(data, dict):
+ return {k: remove_fields(v, fields)
+ for k, v in data.items() if k not in fields}
+ elif isinstance(data, list):
+ return [remove_fields(item, fields) for item in data]
+ return data
+
+def print_toc(tree: List[Dict[str, Any]], indent: int = 0) -> None:
+ """Print Table of Contents to stdout."""
+ for node in tree:
+ print(' ' * indent + str(node.get('title', '')))
+ if node.get('nodes'):
+ print_toc(node['nodes'], indent + 1)
+
+def print_json(data: Any, max_len: int = 40, indent: int = 2) -> None:
+ """Pretty print JSON with truncated strings."""
+ def simplify_data(obj: Any) -> Any:
+ if isinstance(obj, dict):
+ return {k: simplify_data(v) for k, v in obj.items()}
+ elif isinstance(obj, list):
+ return [simplify_data(item) for item in obj]
+ elif isinstance(obj, str) and len(obj) > max_len:
+ return obj[:max_len] + '...'
+ else:
+ return obj
+
+ simplified = simplify_data(data)
+ print(json.dumps(simplified, indent=indent, ensure_ascii=False))
+
+
+def print_wrapped(text: Any, width: int = 100) -> None:
+ """Print text wrapped to specified width."""
+ import textwrap
+
+ if text is None:
+ return
+ for line in str(text).splitlines():
+ if not line.strip():
+ print()
+ continue
+ for wrapped in textwrap.wrap(line, width=width):
+ print(wrapped)
+
+
+def print_tree(tree: List[Dict[str, Any]], exclude_fields: Optional[List[str]] = None, indent: int = 0, max_summary_len: int = 120) -> None:
+ """Print tree structure with node IDs and summaries."""
+ if exclude_fields:
+ # Cast to Any to satisfy mypy since remove_fields returns Structure
+ tree = remove_fields(tree, fields=exclude_fields) # type: ignore
+
+ for node in tree:
+ node_id = node.get('node_id', '')
+ title = node.get('title', '')
+ start = node.get('start_index')
+ end = node.get('end_index')
+ summary = node.get('summary') or node.get('prefix_summary')
+ page_range = None
+ if start is not None and end is not None:
+ page_range = start if start == end else f"{start}-{end}"
+ line = f"{node_id}\t{page_range}\t{title}" if page_range else f"{node_id}\t{title}"
+ if summary:
+ short_summary = summary if len(summary) <= max_summary_len else summary[:max_summary_len] + '...'
+ line = f"{line} — {short_summary}"
+ print(' ' * indent + line)
+ if node.get('nodes'):
+ print_tree(node['nodes'], exclude_fields=exclude_fields, indent=indent + 1, max_summary_len=max_summary_len)
+
+
+def create_node_mapping(tree: List[Dict[str, Any]], include_page_ranges: bool = False, max_page: Optional[int] = None) -> Dict[str, Any]:
+ """Create a dictionary mapping node_ids to nodes."""
+ mapping = {}
+
+ def clamp_page(value: Optional[int]) -> Optional[int]:
+ if value is None or max_page is None:
+ return value
+ return max(1, min(value, max_page))
+
+ def visit(node: Dict[str, Any]) -> None:
+ node_id = node.get('node_id')
+ if node_id:
+ if include_page_ranges:
+ start = clamp_page(node.get('start_index'))
+ end = clamp_page(node.get('end_index'))
+ mapping[node_id] = {
+ 'node': node,
+ 'start_index': start,
+ 'end_index': end,
+ }
+ else:
+ mapping[node_id] = node
+ for child in node.get('nodes') or []:
+ visit(child)
+
+ for root in tree:
+ visit(root)
+
+ return mapping
+
+
+def remove_structure_text(data: Structure) -> Structure:
+ """Recursively remove 'text' field."""
+ if isinstance(data, dict):
+ data.pop('text', None)
+ if 'nodes' in data:
+ remove_structure_text(data['nodes'])
+ elif isinstance(data, list):
+ for item in data:
+ remove_structure_text(item)
+ return data
+
+
+def check_token_limit(structure: Structure, limit: int = 110000) -> None:
+ """Check if any node exceeds the token limit."""
+ flat_list = structure_to_list(structure)
+ for node in flat_list:
+ text = node.get('text', '')
+ num_tokens = count_tokens(text, model='gpt-4o')
+ if num_tokens > limit:
+ print(f"Node ID: {node.get('node_id')} has {num_tokens} tokens")
+ print("Start Index:", node.get('start_index'))
+ print("End Index:", node.get('end_index'))
+ print("Title:", node.get('title'))
+ print("\n")
+
+
+def convert_physical_index_to_int(data: Any) -> Any:
+ """Convert physical_index strings (e.g., '') to integers inplace."""
+ if isinstance(data, list):
+ for i in range(len(data)):
+ # Check if item is a dictionary and has 'physical_index' key
+ if isinstance(data[i], dict) and 'physical_index' in data[i]:
+ if isinstance(data[i]['physical_index'], str):
+ if data[i]['physical_index'].startswith('').strip())
+ elif data[i]['physical_index'].startswith('physical_index_'):
+ data[i]['physical_index'] = int(data[i]['physical_index'].split('_')[-1].strip())
+ elif isinstance(data, str):
+ if data.startswith('').strip())
+ elif data.startswith('physical_index_'):
+ data = int(data.split('_')[-1].strip())
+ # Check data is int
+ if isinstance(data, int):
+ return data
+ else:
+ return None
+ return data
+
+
+def convert_page_to_int(data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
+ """Convert 'page' field to int if possible."""
+ for item in data:
+ if 'page' in item and isinstance(item['page'], str):
+ try:
+ item['page'] = int(item['page'])
+ except ValueError:
+ # Keep original value if conversion fails
+ pass
+ return data
+
+from .pdf import get_text_of_pdf_pages, get_text_of_pdf_pages_with_labels
+
+def add_node_text(node: Structure, pdf_pages: List[Any]) -> None:
+ """Recursively add text to nodes from pdf_pages list based on page range."""
+ if isinstance(node, dict):
+ start_page = node.get('start_index')
+ end_page = node.get('end_index')
+ if start_page is not None and end_page is not None:
+ node['text'] = get_text_of_pdf_pages(pdf_pages, start_page, end_page)
+ if 'nodes' in node:
+ add_node_text(node['nodes'], pdf_pages)
+ elif isinstance(node, list):
+ for index in range(len(node)):
+ add_node_text(node[index], pdf_pages)
+ return
+
+
+def add_node_text_with_labels(node: Structure, pdf_pages: List[Any]) -> None:
+ """Recursively add text with physical index labels."""
+ if isinstance(node, dict):
+ start_page = node.get('start_index')
+ end_page = node.get('end_index')
+ if start_page is not None and end_page is not None:
+ node['text'] = get_text_of_pdf_pages_with_labels(pdf_pages, start_page, end_page)
+ if 'nodes' in node:
+ add_node_text_with_labels(node['nodes'], pdf_pages)
+ elif isinstance(node, list):
+ for index in range(len(node)):
+ add_node_text_with_labels(node[index], pdf_pages)
+ return
+
+
+async def generate_node_summary(node: Dict[str, Any], model: Optional[str] = None) -> str:
+ """Generate summary for a node using LLM."""
+ # Ensure text exists
+ text = node.get('text', '')
+ prompt = f"""You are given a part of a document, your task is to generate a description of the partial document about what are main points covered in the partial document.
+
+ Partial Document Text: {text}
+
+ Directly return the description, do not include any other text.
+ """
+ # Note: model name should ideally be passed, default handled in API
+ response = await ChatGPT_API_async(model or "gpt-4o", prompt)
+ return response
+
+
+async def generate_summaries_for_structure(structure: Structure, model: Optional[str] = None) -> Structure:
+ """Generate summaries for all nodes in the structure."""
+ nodes = structure_to_list(structure)
+ tasks = [generate_node_summary(node, model=model) for node in nodes]
+ summaries = await asyncio.gather(*tasks)
+
+ for node, summary in zip(nodes, summaries):
+ node['summary'] = summary
+ return structure
+
+
+def create_clean_structure_for_description(structure: Structure) -> Structure:
+ """
+ Create a clean structure for document description generation,
+ excluding unnecessary fields like 'text'.
+ """
+ if isinstance(structure, dict):
+ clean_node: Dict[str, Any] = {}
+ # Only include essential fields for description
+ for key in ['title', 'node_id', 'summary', 'prefix_summary']:
+ if key in structure:
+ clean_node[key] = structure[key]
+
+ # Recursively process child nodes
+ if 'nodes' in structure and structure['nodes']:
+ clean_node['nodes'] = create_clean_structure_for_description(structure['nodes'])
+
+ return clean_node
+ elif isinstance(structure, list):
+ return [create_clean_structure_for_description(item) for item in structure] # type: ignore
+ else:
+ return structure
+
+
+def generate_doc_description(structure: Structure, model: str = "gpt-4o") -> str:
+ """Generate a one-sentence description for the entire document structure."""
+ prompt = f"""Your are an expert in generating descriptions for a document.
+ You are given a structure of a document. Your task is to generate a one-sentence description for the document, which makes it easy to distinguish the document from other documents.
+
+ Document Structure: {structure}
+
+ Directly return the description, do not include any other text.
+ """
+ response = ChatGPT_API(model, prompt)
+ return response
+
+
+def reorder_dict(data: Dict[str, Any], key_order: List[str]) -> Dict[str, Any]:
+ """Reorder dictionary keys."""
+ if not key_order:
+ return data
+ return {key: data[key] for key in key_order if key in data}
+
+
+def format_structure(structure: Structure, order: Optional[List[str]] = None) -> Structure:
+ """Recursively format and reorder keys in the structure."""
+ if not order:
+ return structure
+ if isinstance(structure, dict):
+ if 'nodes' in structure:
+ structure['nodes'] = format_structure(structure['nodes'], order)
+ if not structure.get('nodes'):
+ structure.pop('nodes', None)
+ structure = reorder_dict(structure, order)
+ elif isinstance(structure, list):
+ structure = [format_structure(item, order) for item in structure] # type: ignore
+ return structure
diff --git a/pageindex/page_index.py b/src/pageindex/page_index.py
similarity index 99%
rename from pageindex/page_index.py
rename to src/pageindex/page_index.py
index 882fb5dea..c06326e9c 100644
--- a/pageindex/page_index.py
+++ b/src/pageindex/page_index.py
@@ -4,7 +4,10 @@
import math
import random
import re
-from .utils import *
+from .core.llm import ChatGPT_API, ChatGPT_API_with_finish_reason, ChatGPT_API_async, extract_json, count_tokens, get_json_content
+from .core.tree import convert_page_to_int, convert_physical_index_to_int, add_node_text, add_node_text_with_labels
+from .core.pdf import get_number_of_pages, get_pdf_title, get_page_tokens, get_text_of_pages, get_first_start_page_from_text, get_last_start_page_from_text
+from .core.logging import JsonLogger
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
diff --git a/pageindex/page_index_md.py b/src/pageindex/page_index_md.py
similarity index 96%
rename from pageindex/page_index_md.py
rename to src/pageindex/page_index_md.py
index 70e8de086..d891f1d8c 100644
--- a/pageindex/page_index_md.py
+++ b/src/pageindex/page_index_md.py
@@ -2,10 +2,9 @@
import json
import re
import os
-try:
- from .utils import *
-except:
- from utils import *
+
+from .core.llm import count_tokens
+from .core.tree import structure_to_list, write_node_id, format_structure, create_clean_structure_for_description, generate_doc_description, generate_node_summary
async def get_node_summary(node, summary_token_threshold=200, model=None):
node_text = node.get('text')
@@ -303,7 +302,7 @@ async def md_to_tree(md_path, if_thinning=False, min_token_threshold=None, if_ad
# MD_NAME = 'Detect-Order-Construct'
MD_NAME = 'cognitive-load'
- MD_PATH = os.path.join(os.path.dirname(__file__), '..', 'tests/markdowns/', f'{MD_NAME}.md')
+ MD_PATH = os.path.join(os.path.dirname(__file__), '..', '..', 'data', 'markdowns', f'{MD_NAME}.md')
MODEL="gpt-4.1"
@@ -330,10 +329,10 @@ async def md_to_tree(md_path, if_thinning=False, min_token_threshold=None, if_ad
print('='*60)
print_toc(tree_structure['structure'])
- output_path = os.path.join(os.path.dirname(__file__), '..', 'results', f'{MD_NAME}_structure.json')
+ output_path = os.path.join(os.path.dirname(__file__), '..', '..', 'data', 'results', f'{MD_NAME}_structure.json')
os.makedirs(os.path.dirname(output_path), exist_ok=True)
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(tree_structure, f, indent=2, ensure_ascii=False)
- print(f"\nTree structure saved to: {output_path}")
\ No newline at end of file
+ print(f"\nTree structure saved to: {output_path}")
diff --git a/src/pageindex/utils.py b/src/pageindex/utils.py
new file mode 100644
index 000000000..4b999b7db
--- /dev/null
+++ b/src/pageindex/utils.py
@@ -0,0 +1,5 @@
+from .core.llm import *
+from .core.pdf import *
+from .core.tree import *
+from .core.logging import *
+from .config import ConfigLoader
diff --git a/src/refactor_notebooks_logic.py b/src/refactor_notebooks_logic.py
new file mode 100644
index 000000000..bc5ffdc59
--- /dev/null
+++ b/src/refactor_notebooks_logic.py
@@ -0,0 +1,89 @@
+import json
+import glob
+import os
+
+def refactor_notebook(path):
+ print(f"Refactoring {path}...")
+ with open(path, 'r', encoding='utf-8') as f:
+ nb = json.load(f)
+
+ # 1. Inject Imports Cell
+ # Check if we already injected it
+ first_code_cell_idx = -1
+ for i, cell in enumerate(nb['cells']):
+ if cell['cell_type'] == 'code':
+ first_code_cell_idx = i
+ break
+
+ if first_code_cell_idx != -1:
+ # Check source content
+ source = "".join(nb['cells'][first_code_cell_idx]['source'])
+ if "local_client_adapter" not in source:
+ # Create new cell or prepend to first cell?
+ # Better to prepend to first code cell source if it's imports
+ # Or insert new cell before it.
+ new_source = [
+ "import sys\n",
+ "import os\n",
+ "sys.path.append(os.path.abspath('../src'))\n",
+ "from local_client_adapter import get_client\n",
+ "\n"
+ ]
+ # nb['cells'].insert(first_code_cell_idx, {
+ # 'cell_type': 'code',
+ # 'execution_count': None,
+ # 'metadata': {},
+ # 'outputs': [],
+ # 'source': new_source
+ # })
+ # Actually safer to append to the start of the existing imports cell if strictly needed,
+ # but inserting a new cell is cleaner.
+ nb['cells'].insert(first_code_cell_idx, {
+ 'cell_type': 'code',
+ 'execution_count': None,
+ 'metadata': {},
+ 'outputs': [],
+ 'source': new_source
+ })
+
+ # 2. Key replacements in all code cells
+ for cell in nb['cells']:
+ if cell['cell_type'] == 'code':
+ new_source = []
+ for line in cell['source']:
+ # Replace imports
+ if "from pageindex import PageIndexClient" in line:
+ line = line.replace("from pageindex import PageIndexClient", "# from pageindex import PageIndexClient")
+
+ # Replace client init
+ if "PageIndexClient(" in line:
+ line = line.replace("PageIndexClient(", "get_client(")
+
+ # Fix JsonExtractor if present
+ if "from json_extractor import JsonExtractor" in line:
+ line = "# from json_extractor import JsonExtractor\nfrom pageindex.core.llm import extract_json, get_json_content\n"
+
+ if "JsonExtractor.extract_valid_json" in line:
+ line = line.replace("JsonExtractor.extract_valid_json", "extract_json")
+
+ # Comment out pip installs
+ if "%pip install" in line:
+ line = "# " + line
+
+ new_source.append(line)
+ cell['source'] = new_source
+
+ with open(path, 'w', encoding='utf-8') as f:
+ json.dump(nb, f, indent=1, ensure_ascii=False)
+ print(f"Saved {path}")
+
+if __name__ == "__main__":
+ files = glob.glob("../notebooks/*.ipynb")
+ for f in files:
+ if "pageindex_RAG_simple" in f:
+ # Skip this one or handle differently?
+ # It has no PageIndexClient import in my analysis?
+ # Wait, Cell 9 has: from pageindex import PageIndexClient
+ # So it DOES use it. It should be refactored too.
+ pass
+ refactor_notebook(f)
diff --git a/src/verify_adapter.py b/src/verify_adapter.py
new file mode 100644
index 000000000..6a1736b16
--- /dev/null
+++ b/src/verify_adapter.py
@@ -0,0 +1,22 @@
+import sys
+import os
+sys.path.append(os.path.abspath('.'))
+from local_client_adapter import get_client
+
+def test_adapter():
+ print("Testing Local Adapter...")
+ client = get_client(api_key="TEST")
+ print("Client initialized.")
+
+ # Check methods exist
+ assert hasattr(client, 'submit_document')
+ assert hasattr(client, 'get_tree')
+ assert hasattr(client, 'chat_completions')
+ print("Methods verified.")
+
+ # We can't easily test submit_document without a real file and openai key (which might be missing or mocking needed)
+ # But we can verify imports are working.
+ print("Imports and class structure verified.")
+
+if __name__ == "__main__":
+ test_adapter()
diff --git a/tests/conftest.py b/tests/conftest.py
new file mode 100644
index 000000000..94d322bfe
--- /dev/null
+++ b/tests/conftest.py
@@ -0,0 +1,6 @@
+import pytest
+import os
+import sys
+
+# Add src to python path for testing
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "../src")))
diff --git a/tests/test_config.py b/tests/test_config.py
new file mode 100644
index 000000000..ffe4f23c8
--- /dev/null
+++ b/tests/test_config.py
@@ -0,0 +1,39 @@
+import pytest
+from types import SimpleNamespace
+from pageindex.config import ConfigLoader, PageIndexConfig
+
+def test_config_loader_default(tmp_path):
+ # Mock config file
+ config_file = tmp_path / "config.yaml"
+ config_file.write_text('model: "gpt-4-test"\nmax_page_num_each_node: 10', encoding="utf-8")
+
+ loader = ConfigLoader(default_path=config_file)
+ cfg = loader.load()
+
+ assert isinstance(cfg, PageIndexConfig)
+ assert cfg.model == "gpt-4-test"
+ assert cfg.max_page_num_each_node == 10
+ # Check default logic
+ assert cfg.toc_check_page_num == 3
+
+def test_config_loader_override():
+ loader = ConfigLoader(default_path=None)
+ override = {"model": "gpt-override", "if_add_node_id": False}
+
+ cfg = loader.load(user_opt=override)
+ assert cfg.model == "gpt-override"
+ assert cfg.if_add_node_id is False
+
+def test_config_validation_error():
+ loader = ConfigLoader(default_path=None)
+ # Pass invalid type for integer field
+ override = {"max_page_num_each_node": "not-an-int"}
+
+ with pytest.raises(ValueError, match="Configuration validation failed"):
+ loader.load(user_opt=override)
+
+def test_partial_override_object():
+ args = SimpleNamespace(model="cmd-model", other_arg=None)
+ loader = ConfigLoader(default_path=None)
+ cfg = loader.load(user_opt=args)
+ assert cfg.model == "cmd-model"
diff --git a/tests/test_llm.py b/tests/test_llm.py
new file mode 100644
index 000000000..c8feb3a35
--- /dev/null
+++ b/tests/test_llm.py
@@ -0,0 +1,21 @@
+import pytest
+from pageindex.core.llm import extract_json, count_tokens
+
+def test_extract_json_basic():
+ text = '{"key": "value"}'
+ assert extract_json(text) == {"key": "value"}
+
+def test_extract_json_with_markdown():
+ text = 'Here is the json:\n```json\n{"key": "value"}\n```'
+ assert extract_json(text) == {"key": "value"}
+
+def test_extract_json_with_trailing_commas():
+ # This might fail depending on implementation robustness, but let's see
+ text = '{"key": "value",}'
+ # Our implementation tries to fix this
+ assert extract_json(text) == {"key": "value"}
+
+def test_count_tokens():
+ text = "Hello world"
+ # Basic check, exact number depends on encoding
+ assert count_tokens(text) > 0
diff --git a/tests/test_tree.py b/tests/test_tree.py
new file mode 100644
index 000000000..defb67ceb
--- /dev/null
+++ b/tests/test_tree.py
@@ -0,0 +1,36 @@
+import pytest
+from pageindex.core.tree import list_to_tree, structure_to_list, get_nodes, write_node_id
+
+@pytest.fixture
+def sample_structure():
+ return [
+ {"structure": "1", "title": "Chapter 1", "start_index": 1, "end_index": 5},
+ {"structure": "1.1", "title": "Section 1.1", "start_index": 1, "end_index": 3},
+ {"structure": "1.2", "title": "Section 1.2", "start_index": 4, "end_index": 5},
+ {"structure": "2", "title": "Chapter 2", "start_index": 6, "end_index": 10}
+ ]
+
+def test_list_to_tree(sample_structure):
+ tree = list_to_tree(sample_structure)
+ assert len(tree) == 2
+ assert tree[0]["title"] == "Chapter 1"
+ assert len(tree[0]["nodes"]) == 2
+ assert tree[0]["nodes"][0]["title"] == "Section 1.1"
+ assert tree[1]["title"] == "Chapter 2"
+ assert "nodes" not in tree[1] or len(tree[1]["nodes"]) == 0
+
+def test_structure_to_list(sample_structure):
+ tree = list_to_tree(sample_structure)
+ flat_list = structure_to_list(tree)
+ # Note: structure_to_list might not preserve original order exactly or might include container nodes
+ # But for our simple case it should be close.
+ assert len(flat_list) == 4
+ titles = [item["title"] for item in flat_list]
+ assert "Chapter 1" in titles
+ assert "Section 1.1" in titles
+
+def test_write_node_id(sample_structure):
+ tree = list_to_tree(sample_structure)
+ write_node_id(tree)
+ assert tree[0]["node_id"] == "0000"
+ assert tree[0]["nodes"][0]["node_id"] == "0001"
diff --git a/tutorials/doc-search/README.md b/tutorials/doc-search/README.md
deleted file mode 100644
index b24033ea5..000000000
--- a/tutorials/doc-search/README.md
+++ /dev/null
@@ -1,17 +0,0 @@
-
-
-## Document Search Examples
-
-
-PageIndex currently enables reasoning-based RAG within a single document by default.
-For users who need to search across multiple documents, we provide three best-practice workflows for different scenarios below.
-
-* [**Search by Metadata**:](metadata.md) for documents that can be distinguished by metadata.
-* [**Search by Semantics**:](semantics.md) for documents with different semantic content or cover diverse topics.
-* [**Search by Description**:](description.md) a lightweight strategy for a small number of documents.
-
-
-## 💬 Support
-
-* 🤝 [Join our Discord](https://discord.gg/VuXuf29EUj)
-* 📨 [Contact Us](https://ii2abc2jejf.typeform.com/to/meB40zV0)
\ No newline at end of file
diff --git a/tutorials/doc-search/description.md b/tutorials/doc-search/description.md
deleted file mode 100644
index cffcdeee5..000000000
--- a/tutorials/doc-search/description.md
+++ /dev/null
@@ -1,67 +0,0 @@
-
-## Document Search by Description
-
-For documents that don't have metadata, you can use LLM-generated descriptions to help with document selection. This is a lightweight approach that works best with a small number of documents.
-
-
-### Example Pipeline
-
-
-#### PageIndex Tree Generation
-Upload all documents into PageIndex to get their `doc_id` and tree structure.
-
-#### Description Generation
-
-Generate a description for each document based on its PageIndex tree structure and node summaries.
-```python
-prompt = f"""
-You are given a table of contents structure of a document.
-Your task is to generate a one-sentence description for the document that makes it easy to distinguish from other documents.
-
-Document tree structure: {PageIndex_Tree}
-
-Directly return the description, do not include any other text.
-"""
-```
-
-#### Search with LLM
-
-Use an LLM to select relevant documents by comparing the user query against the generated descriptions.
-
-Below is a sample prompt for document selection based on their descriptions:
-
-```python
-prompt = f"""
-You are given a list of documents with their IDs, file names, and descriptions. Your task is to select documents that may contain information relevant to answering the user query.
-
-Query: {query}
-
-Documents: [
- {
- "doc_id": "xxx",
- "doc_name": "xxx",
- "doc_description": "xxx"
- }
-]
-
-Response Format:
-{{
- "thinking": "",
- "answer": , e.g. ['doc_id1', 'doc_id2']. Return [] if no documents are relevant.
-}}
-
-Return only the JSON structure, with no additional output.
-"""
-```
-
-#### Retrieve with PageIndex
-
-Use the PageIndex `doc_id` of the retrieved documents to perform further retrieval via the PageIndex retrieval API.
-
-
-
-## 💬 Help & Community
-Contact us if you need any advice on conducting document searches for your use case.
-
-- 🤝 [Join our Discord](https://discord.gg/VuXuf29EUj)
-- 📨 [Leave us a message](https://ii2abc2jejf.typeform.com/to/meB40zV0)
\ No newline at end of file
diff --git a/tutorials/doc-search/metadata.md b/tutorials/doc-search/metadata.md
deleted file mode 100644
index 2bc18a16e..000000000
--- a/tutorials/doc-search/metadata.md
+++ /dev/null
@@ -1,37 +0,0 @@
-
-
-## Document Search by Metadata
-PageIndex with metadata support is in closed beta. Fill out this form to request early access to this feature.
-
-For documents that can be easily distinguished by metadata, we recommend using metadata to search the documents.
-This method is ideal for the following document types:
-- Financial reports categorized by company and time period
-- Legal documents categorized by case type
-- Medical records categorized by patient or condition
-- And many others
-
-In such cases, you can search documents by leveraging their metadata. A popular method is to use "Query to SQL" for document retrieval.
-
-
-### Example Pipeline
-
-#### PageIndex Tree Generation
-Upload all documents into PageIndex to get their `doc_id`.
-
-#### Set up SQL tables
-
-Store documents along with their metadata and the PageIndex `doc_id` in a database table.
-
-#### Query to SQL
-
-Use an LLM to transform a user’s retrieval request into a SQL query to fetch relevant documents.
-
-#### Retrieve with PageIndex
-
-Use the PageIndex `doc_id` of the retrieved documents to perform further retrieval via the PageIndex retrieval API.
-
-## 💬 Help & Community
-Contact us if you need any advice on conducting document searches for your use case.
-
-- 🤝 [Join our Discord](https://discord.gg/VuXuf29EUj)
-- 📨 [Leave us a message](https://ii2abc2jejf.typeform.com/to/meB40zV0)
\ No newline at end of file
diff --git a/tutorials/doc-search/semantics.md b/tutorials/doc-search/semantics.md
deleted file mode 100644
index 6608aeaf0..000000000
--- a/tutorials/doc-search/semantics.md
+++ /dev/null
@@ -1,41 +0,0 @@
-## Document Search by Semantics
-
-For documents that cover diverse topics, one can also use vector-based semantic search to search the documents. The procedure is slightly different from the classic vector-search-based method.
-
-### Example Pipeline
-
-
-#### Chunking and Embedding
-Divide the documents into chunks, choose an embedding model to convert the chunks into vectors and store each vector with its corresponding `doc_id` in a vector database.
-
-
-#### Vector Search
-
-For each query, conduct a vector-based search to get top-K chunks with their corresponding documents.
-
-#### Compute Document Score
-
-For each document, calculate a relevance score. Let N be the number of content chunks associated with each document, and let **ChunkScore**(n) be the relevance score of chunk n. The document score is computed as:
-
-
-$$
-\text{DocScore}=\frac{1}{\sqrt{N+1}}\sum_{n=1}^N \text{ChunkScore}(n)
-$$
-
-- The sum aggregates relevance from all related chunks.
-- The +1 inside the square root ensures the formula handles nodes with zero chunks.
-- Using the square root in the denominator allows the score to increase with the number of relevant chunks, but with diminishing returns. This rewards documents with more relevant chunks, while preventing large nodes from dominating due to quantity alone.
-- This scoring favors documents with fewer, highly relevant chunks over those with many weakly relevant ones.
-
-
-#### Retrieve with PageIndex
-
-Select the documents with the highest DocScore, then use their `doc_id` to perform further retrieval via the PageIndex retrieval API.
-
-
-
-## 💬 Help & Community
-Contact us if you need any advice on conducting document searches for your use case.
-
-- 🤝 [Join our Discord](https://discord.gg/VuXuf29EUj)
-- 📨 [Leave us a message](https://ii2abc2jejf.typeform.com/to/meB40zV0)
\ No newline at end of file
diff --git a/tutorials/tree-search/README.md b/tutorials/tree-search/README.md
deleted file mode 100644
index a85545df9..000000000
--- a/tutorials/tree-search/README.md
+++ /dev/null
@@ -1,70 +0,0 @@
-## Tree Search Examples
-This tutorial provides a basic example of how to perform retrieval using the PageIndex tree.
-
-### Basic LLM Tree Search Example
-A simple strategy is to use an LLM agent to conduct tree search. Here is a basic tree search prompt.
-
-```python
-prompt = f"""
-You are given a query and the tree structure of a document.
-You need to find all nodes that are likely to contain the answer.
-
-Query: {query}
-
-Document tree structure: {PageIndex_Tree}
-
-Reply in the following JSON format:
-{{
- "thinking": ,
- "node_list": [node_id1, node_id2, ...]
-}}
-"""
-```
-
-In our dashboard and retrieval API, we use a combination of LLM tree search and value function-based Monte Carlo Tree Search ([MCTS](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search)). More details will be released soon.
-
-
-### Integrating User Preference or Expert Knowledge
-Unlike vector-based RAG where integrating expert knowledge or user preference requires fine-tuning the embedding model, in PageIndex, you can incorporate user preferences or expert knowledge by simply adding knowledge to the LLM tree search prompt. Here is an example pipeline.
-
-
-#### 1. Preference Retrieval
-
-When a query is received, the system selects the most relevant user preference or expert knowledge snippets from a database or a set of domain-specific rules. This can be done using keyword matching, semantic similarity, or LLM-based relevance search.
-
-#### 2. Tree Search with Preference
-Integrating preference into the tree search prompt.
-
-**Enhanced Tree Search with Expert Preference Example**
-
-```python
-prompt = f"""
-You are given a question and a tree structure of a document.
-You need to find all nodes that are likely to contain the answer.
-
-Query: {query}
-
-Document tree structure: {PageIndex_Tree}
-
-Expert Knowledge of relevant sections: {Preference}
-
-Reply in the following JSON format:
-{{
- "thinking": ,
- "node_list": [node_id1, node_id2, ...]
-}}
-"""
-```
-
-**Example Expert Preference**
-> If the query mentions EBITDA adjustments, prioritize Item 7 (MD&A) and footnotes in Item 8 (Financial Statements) in 10-K reports.
-
-
-
-By integrating user or expert preferences, node search becomes more targeted and effective, leveraging both the document structure and domain-specific insights.
-
-## 💬 Help & Community
-Contact us if you need any advice on conducting document searches for your use case.
-
-- 🤝 [Join our Discord](https://discord.gg/VuXuf29EUj)
-- 📨 [Leave us a message](https://ii2abc2jejf.typeform.com/to/tK3AXl8T)
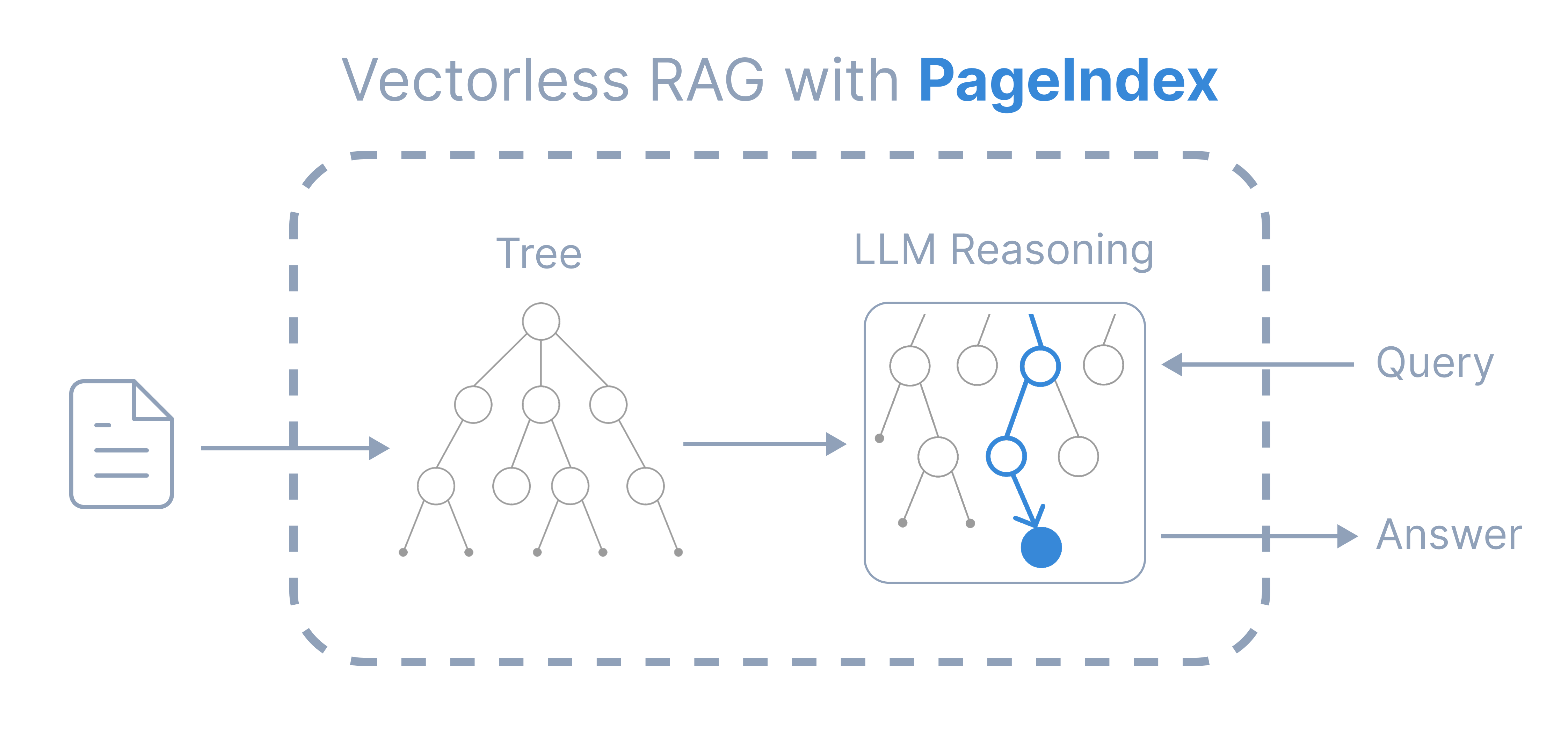 -
-
-
-