|
| 1 | +export const meta = { |
| 2 | + id: "splitgraph-matomo-elasticsearch-metabase", |
| 3 | + title: "Dogfooding Splitgraph at Splitgraph for cross-database analytics", |
| 4 | + date: "2020-09-18", |
| 5 | + authors: ["Artjoms Iškovs"], |
| 6 | + topics: ["technical", "analytics"], |
| 7 | + description: |
| 8 | + "We talk about how we use Metabase, Splitgraph and PostgreSQL foreign data wrappers to build BI " + |
| 9 | + "dashboards that are backed by federated queries across our Matomo and Elasticsearch instances.", |
| 10 | + related: ["introduction-to-splitgraph", "data-delivery-network", "data-delivery-network-launch", "dbt"], |
| 11 | +}; |
| 12 | + |
| 13 | +[Splitgraph](https://www.splitgraph.com) is powered by data. We use [Metabase](https://www.metabase.com/) to build BI dashboards that can answer questions about how people interact with us. These dashboards reference our Web analytics data, user data and all events happening across the estate. We can find out how many people queried the Splitgraph [Data Delivery Network](https://www.splitgraph.com/connect) on a given week, how they found Splitgraph, or if they ever pulled a data image. |
| 14 | + |
| 15 | +This works without any ETL pipelines or a data warehouse. How do we do it? |
| 16 | + |
| 17 | +Well, we use Splitgraph. |
| 18 | + |
| 19 | +In this post, we'll talk about our analytics stack. We'll discuss how we use Splitgraph's [`sgr mount`](https://www.splitgraph.com/docs/ingesting-data/foreign-data-wrappers/introduction) command to proxy to data from Matomo, Elasticsearch and PostgreSQL. We'll show a sample SQL query that runs a federated JOIN between these three databases. Finally, we'll talk about how we use Metabase to get a clear view of the business. |
| 20 | + |
| 21 | +## Our analytics stack |
| 22 | + |
| 23 | +We hate third-party trackers. At the same time, we would like to know what's happening on the website and across the company in general. In the age of CDNs, a visit to a website might never reach the origin server. HTTP server logs won't show the full story about website visitors. |
| 24 | + |
| 25 | +To solve that, we started using **[Matomo](https://matomo.org/)**. Matomo is an open-source web analytics platform. It offers a similar interface and feature set to Google Analytics. However, unlike GA, it stores all data locally in a MySQL database. |
| 26 | + |
| 27 | +Besides visiting the website, there's a lot of other ways users can interact with Splitgraph. For example: |
| 28 | + |
| 29 | + * Starring Splitgraph on GitHub or downloading a release |
| 30 | + * Querying the Splitgraph [Data Delivery Network](https://www.splitgraph.com/connect) from an SQL client |
| 31 | + * Pushing and pulling [data images](https://splitgraph.com/docs/concepts/images) to/from Splitgraph |
| 32 | + * Using the [REST API](https://www.splitgraph.com/docs/splitgraph-cloud/publish-rest-api) |
| 33 | + * Checking for updates: we use this to estimate the number of active `sgr` users |
| 34 | + |
| 35 | +We use **Elasticsearch** to log these and other interesting events. |
| 36 | + |
| 37 | +Finally, we have a **PostgreSQL** database that stores actual user data. Some of it could be useful to know in an analytics context. For example: a user's primary e-mail address or their GitHub ID. |
| 38 | + |
| 39 | +## How to bring the data together? |
| 40 | + |
| 41 | +The idea for this setup came to us when we were trying to get some data from the Matomo Web UI. While it is pretty powerful, it's limited in the kinds of reports it can produce. Also, data we'd see in Matomo didn't include anything we store in Elasticsearch. |
| 42 | + |
| 43 | +We wondered if we could query the data from Matomo's MySQL database directly. The [schema](https://developer.matomo.org/guides/database-schema), albeit complex, is well documented on their website. |
| 44 | + |
| 45 | +We could ingest data into Elasticsearch. However, we were already using Kibana to visualize Elasticsearch data and its visualizations were sometimes frustrating to use. Basic functionality like plotting sums is only available through scripted Elasticsearch fields. |
| 46 | + |
| 47 | + |
| 48 | +_Pictured: five different visualization engines that Kibana lets you use_ |
| 49 | + |
| 50 | +But then we thought about it some more. Splitgraph itself is built on top of PostgreSQL. One of its features is making PostgreSQL [foreign data wrappers](https://www.splitgraph.com/blog/foreign-data-wrappers) more user-friendly. Splitgraph's `sgr mount` lets you instantiate an FDW with a single command. You can then query the data directly or snapshot it. |
| 51 | + |
| 52 | +Could we use a Splitgraph instance and add a MySQL FDW to it to query Matomo data? |
| 53 | + |
| 54 | +And if we did, could we use an Elasticsearch FDW to proxy to our events data? |
| 55 | + |
| 56 | +And if we did that, could we use something like [Metabase](https://www.metabase.com/) and point it at Splitgraph, letting it query data across all our data silos? |
| 57 | + |
| 58 | +Turns out, we could. Here's an abridged version of how we mount Matomo data on a Splitgraph instance. We have a full set of commands on [our GitHub](https://github.com/splitgraph/splitgraph/tree/master/examples/cross-db-analytics). |
| 59 | + |
| 60 | +``` |
| 61 | +sgr mount mysql_fdw matomo_raw -c matomo:$PASSWORD@matomo-db -o@- <<EOF |
| 62 | +{ |
| 63 | + "remote_schema": "matomo", |
| 64 | + "tables": { |
| 65 | + "matomo_log_action": { |
| 66 | + "hash": "bigint", |
| 67 | + "idaction": "integer", |
| 68 | + "name": "character varying(4096)", |
| 69 | + "type": "smallint", |
| 70 | + "url_prefix": "smallint" |
| 71 | + }, |
| 72 | + "matomo_log_visit": { |
| 73 | + "idvisit": "bigint", |
| 74 | + "idvisitor": "bytea", |
| 75 | + "user_id": "character varying(200)", |
| 76 | + "location_ip": "bytea", |
| 77 | + "referer_url": "text", |
| 78 | + "visit_entry_idaction_name": "integer", |
| 79 | + "visit_entry_idaction_url": "integer", |
| 80 | + "visit_exit_idaction_name": "integer", |
| 81 | + "visit_exit_idaction_url": "integer", |
| 82 | + "visit_first_action_time": "timestamp without time zone", |
| 83 | + "visit_last_action_time": "timestamp without time zone", |
| 84 | + "visit_total_actions": "integer", |
| 85 | + "visitor_count_visits": "integer", |
| 86 | + "visitor_days_since_first": "smallint", |
| 87 | + "visitor_days_since_last": "smallint", |
| 88 | + "visitor_returning": "smallint" |
| 89 | + } |
| 90 | + } |
| 91 | +} |
| 92 | +EOF |
| 93 | +``` |
| 94 | + |
| 95 | +In this, we just pull out interesting tables and columns from Matomo. The full Matomo schema spec for Splitgraph is available [here](https://github.com/splitgraph/splitgraph/blob/master/examples/cross-db-analytics/mounting/matomo.json). |
| 96 | + |
| 97 | +To query Elasticsearch, we used a [fork](https://github.com/splitgraph/postgres-elasticsearch-fdw) of `postgres-elasticsearch-fdw` with the ability to push down qualifiers. We made it available as an `sgr mount` subcommand. Here's an example: |
| 98 | + |
| 99 | +``` |
| 100 | +sgr mount elasticsearch -c elasticsearch:9200 -o@- <<EOF |
| 101 | +{ |
| 102 | + "table_spec": { |
| 103 | + "github_scraper_data": { |
| 104 | + "schema": { |
| 105 | + "id": "text", |
| 106 | + "@timestamp": "timestamp", |
| 107 | + "sg.github.stars": "integer", |
| 108 | + "sg.github.issues": "integer", |
| 109 | + "sg.github.downloads_installer": "integer", |
| 110 | + "sg.github.downloads_osx": "integer", |
| 111 | + "sg.github.downloads_linux": "integer", |
| 112 | + "sg.github.downloads_windows": "integer" |
| 113 | + }, |
| 114 | + "index": "sg-misc*", |
| 115 | + "rowid_column": "id" |
| 116 | + } |
| 117 | + } |
| 118 | +} |
| 119 | +EOF |
| 120 | +``` |
| 121 | + |
| 122 | +This creates a table that proxies to the data dumped by our GitHub star scraper. |
| 123 | + |
| 124 | +Adding our PostgreSQL database was easy. We made an analytics user and gave it access a limited amount of useful tables (we wrote about our [configuration and credential generation](https://www.splitgraph.com/blog/integration-tests) before): |
| 125 | + |
| 126 | +``` |
| 127 | +sgr mount postgres_fdw sgr_auth -c [connstr] -o@- <<EOF |
| 128 | +{ |
| 129 | + "dbname": "auth", |
| 130 | + "remote_schema": "sgr_auth", |
| 131 | + "tables": [ |
| 132 | + "user_emails", |
| 133 | + "profiles" |
| 134 | + ], |
| 135 | + "extra_server_args": { |
| 136 | + "use_remote_estimate": "true", |
| 137 | + "fetch_size": "10000" |
| 138 | + } |
| 139 | +} |
| 140 | +EOF |
| 141 | +``` |
| 142 | + |
| 143 | +## Sample queries |
| 144 | + |
| 145 | +Let's now query Elasticsearch from Splitgraph and find out how many GitHub stars Splitgraph has: |
| 146 | + |
| 147 | +```sql |
| 148 | +SELECT "sg.github.stars" |
| 149 | +FROM elasticsearch_raw.github_scraper_data |
| 150 | +ORDER BY "@timestamp" DESC |
| 151 | +LIMIT 1; |
| 152 | + |
| 153 | + sg.github.stars |
| 154 | +----------------- |
| 155 | + 149 |
| 156 | +(1 row) |
| 157 | +``` |
| 158 | + |
| 159 | +Only 149?! Make sure to [star Splitgraph on GitHub](https://github.com/splitgraph/splitgraph) if you're reading this! |
| 160 | + |
| 161 | +### Federated JOIN |
| 162 | + |
| 163 | +As a real-world example, let's say we wanted to: |
| 164 | + |
| 165 | + * Find users that visited our website in the last week |
| 166 | + * Also find out how many queries to our Data Delivery Network they made |
| 167 | + * Find out their e-mail addresses |
| 168 | + |
| 169 | +This data lives across three different databases, as discussed. With this setup, we can bring these three silos together with one simple SQL query: |
| 170 | + |
| 171 | +```sql |
| 172 | +SELECT |
| 173 | + v.user_id, |
| 174 | + email, |
| 175 | + last_visit, |
| 176 | + COALESCE(total_ddn_queries, 0) AS total_ddn_queries |
| 177 | +FROM sgr_auth.user_emails ue |
| 178 | +LEFT OUTER JOIN ( |
| 179 | + -- Get user IDs and how many DDN queries they made |
| 180 | + SELECT "sg.api.user_id" AS user_id, COUNT(1) AS total_ddn_queries |
| 181 | + FROM elasticsearch_raw.sql_api_queries |
| 182 | + WHERE "sg.sql.used_images" IS NOT NULL |
| 183 | + GROUP BY user_id |
| 184 | +) d |
| 185 | +ON ue.user_id::text = d.user_id |
| 186 | +JOIN ( |
| 187 | + -- Get last visit timestamp for users who visited the website |
| 188 | + -- in the last week |
| 189 | + SELECT user_id, MAX(visit_last_action_time) AS last_visit |
| 190 | + FROM matomo_raw.matomo_log_visit v |
| 191 | + WHERE user_id IS NOT NULL |
| 192 | + AND AGE(visit_last_action_time) < '1 week' |
| 193 | + GROUP BY user_id |
| 194 | +) v |
| 195 | +ON ue.user_id::text = v.user_id |
| 196 | +WHERE ue.is_primary IS TRUE |
| 197 | +ORDER BY last_visit DESC; |
| 198 | +``` |
| 199 | + |
| 200 | +Here's the query plan for it: |
| 201 | + |
| 202 | +``` |
| 203 | + Sort |
| 204 | + Sort Key: (max(v.visit_last_action_time)) DESC |
| 205 | + -> Hash Left Join |
| 206 | + Hash Cond: ((ue.user_id)::text = d.user_id) |
| 207 | + -> Hash Join |
| 208 | + Hash Cond: ((ue.user_id)::text = (v.user_id)::text) |
| 209 | + -> Foreign Scan on user_emails ue |
| 210 | + Filter: (is_primary IS TRUE) |
| 211 | + -> Hash |
| 212 | + -> HashAggregate |
| 213 | + Group Key: v.user_id |
| 214 | + -> Foreign Scan on matomo_log_visit v |
| 215 | + Filter: (age((CURRENT_DATE)::timestamp without time zone, visit_last_action_time) < '7 days'::interval) |
| 216 | + -> Hash |
| 217 | + -> Subquery Scan on d |
| 218 | + -> GroupAggregate |
| 219 | + Group Key: sql_api_queries."sg.api.user_id" |
| 220 | + -> Sort |
| 221 | + Sort Key: sql_api_queries."sg.api.user_id" |
| 222 | + -> Foreign Scan on sql_api_queries |
| 223 | + Filter: ("sg.sql.used_images" IS NOT NULL) |
| 224 | + Multicorn: Elasticsearch query to <Elasticsearch([{'host': 'elasticsearch', 'port': 9200}])> |
| 225 | + Multicorn: Query: {"query": {"bool": {"must": [{"exists": {"field": "sg.sql.used_images"}}]}}} |
| 226 | +``` |
| 227 | + |
| 228 | +As you can see, this resolves into a Hash Join across three foreign tables. It also pushes down most of the clauses to the three origin databases: |
| 229 | + |
| 230 | +``` |
| 231 | +[PostgreSQL] |
| 232 | +Foreign Scan on user_emails ue |
| 233 | + Filter: (is_primary IS TRUE) |
| 234 | +
|
| 235 | +[MySQL] |
| 236 | +Foreign Scan on matomo_log_visit v |
| 237 | + Filter: (age((CURRENT_DATE)::timestamp without time zone, visit_last_action_time) < '7 days'::interval) |
| 238 | +
|
| 239 | +[Elasticsearch] |
| 240 | +-> Foreign Scan on sql_api_queries |
| 241 | + Filter: ("sg.sql.used_images" IS NOT NULL) |
| 242 | + Multicorn: Query: {"query": {"bool": {"must": [{"exists": {"field": "sg.sql.used_images"}}]}}} |
| 243 | +``` |
| 244 | + |
| 245 | +Normally, this would require a data warehouse and a few separate ingestion pipelines. With Splitgraph and PostgreSQL, we can query the data at source. This idea is called "data virtualization" or a "data fabric". We call it a "database proxy". |
| 246 | + |
| 247 | +Is data virtualization always the right solution? No, but it should be a starting point. If performance becomes a concern, we'll be able to snapshot these tables as Splitgraph images. Splitgraph stores data in a columnar format (using |
| 248 | +[`cstore_fdw`](https://www.splitgraph.com/docs/concepts/objects)), so we'll be able to query it much faster. |
| 249 | + |
| 250 | +## Data modelling |
| 251 | + |
| 252 | +We wrote a few views on these source foreign tables that wrangle the data and clean it up. For example ([SQL on GitHub](https://github.com/splitgraph/splitgraph/blob/master/examples/cross-db-analytics/mounting/matomo.sql)), we join the Matomo `log_action` and `log_visit` tables to get the URLs of entry and exit pages. The view also formats the IP addresses as strings rather than `bytea` values. |
| 253 | + |
| 254 | +Finally, we wrote a view that joins across multiple tables to give us information on each user and their activity on Splitgraph. This includes their website visits and their activity on the DDN and the Splitgraph registry. |
| 255 | + |
| 256 | +Querying these views still queries live data, but they're much more user friendly to query than the original data sources. One exception is Elasticsearch: there, we materialize some views for performance. |
| 257 | + |
| 258 | +Currently, we build and organize these views ourselves. But there's nothing preventing us from running [dbt](https://www.getdbt.com/) to manage this process better. We wrote a [blog post](https://www.splitgraph.com/blog/dbt) earlier on how to use dbt with Splitgraph. |
| 259 | + |
| 260 | +## Metabase |
| 261 | + |
| 262 | +### Setting up |
| 263 | + |
| 264 | +By far the most difficult thing about setting up Metabase with Splitgraph was getting it served on a non-root path behind a reverse proxy. To save you an hour of perusing GitHub issues, the settings are: |
| 265 | + |
| 266 | + * Make sure your reverse proxy **strips the path prefix**. For example, a request to `https://www.company.com/metabase/admin/datamodel` should be forwarded to `/admin/datamodel`. |
| 267 | + * Make sure your routing doesn't result in paths prefixed with double slashes! |
| 268 | + * Set the `MB_SITE_URL` environment variable to the full base URL, for example, `https://www.company.com/metabase/`. In this case, it must have a **trailing slash**! |
| 269 | + |
| 270 | +### Insights |
| 271 | + |
| 272 | +Besides that, Metabase worked surprisingly well on Splitgraph. We had to add a User ID primary key (on the [Data Model](https://www.metabase.com/docs/latest/administration-guide/03-metadata-editing.html) page) on our main user. After also adding the user ID as a foreign key in a few other views, we got amazing drill down capabilities. |
| 273 | + |
| 274 | +For example, we could plot a graph of daily website visits (picture from the day our [DDN launch blog post](https://news.ycombinator.com/item?id=24233948) was #1 on Hacker News!): |
| 275 | + |
| 276 | +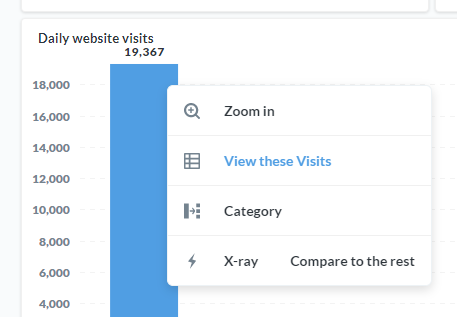 |
| 277 | + |
| 278 | +We could then take a look at visits from that day and see if any of them were already Splitgraph users. Finally, we could click on that user ID and automatically get information on all other activity tables involving that user: |
| 279 | + |
| 280 | +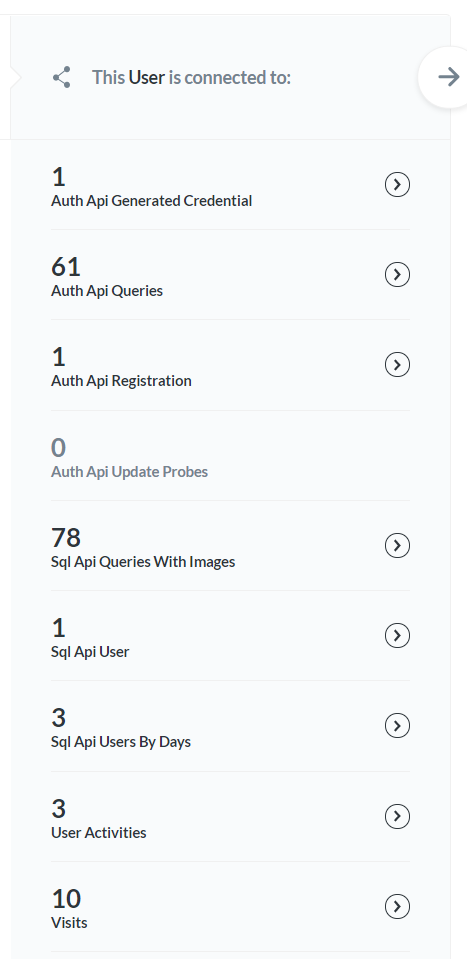 |
| 281 | + |
| 282 | +Metabase didn't care that these tables were actually views on other views on foreign tables. Behind the scenes, this would magically forward data to either Elasticsearch, Matomo or PostgreSQL, depending on what was being queried. |
| 283 | + |
| 284 | +## Conclusion |
| 285 | + |
| 286 | +In this post, we talked about our analytics setup that involves Metabase, Splitgraph itself and multiple backend data sources that we query through PostgreSQL foreign data wrappers. We discussed how it can provide business insights without adding extra complexity. |
| 287 | + |
| 288 | +On [our GitHub](https://github.com/splitgraph/splitgraph/tree/master/examples/cross-db-analytics), you'll find a sample setup that will let you query Matomo data from PostgreSQL. |
| 289 | + |
| 290 | +If you're interested in learning more about Splitgraph, feel free to check our our [website](https://www.splitgraph.com/)! |
0 commit comments